import numpy as np
from matplotlib import pyplot as plt
from matplotlib import patches
import librosa, librosa.display
import pandas as pd
import scipy
from scipy import ndimage
import time
from utils.plot_tools import *
from utils.feature_tools import normalize_feature_sequence, smooth_downsample_feature_sequence, compute_cost_matrix
from utils.structure_tools import compute_tempo_rel_set, read_structure_annotation
import IPython.display as ipd
from IPython.display import Image, Audio
path_img = '../img/8.content-based_audio_retrieval/'
path_data = '../data_FMP/'8.3. 오디오 매칭
Audio Matching
내용 기반
오디오 검색
매칭 함수
크로마그램
내용 기반 오디오 검색 중 다른 연주나 편곡이라도 쿼리와 같은 음악을 찾는 오디오 매칭(audio matching)에 대해 설명한다. CENS와 대각선 매칭(diagonal matching), 하위시퀀스(subsequence) DTW 등에 대해 다룬다.
이 글은 FMP(Fundamentals of Music Processing) Notebooks을 참고로 합니다.
피쳐 디자인(Feature Design) - Chroma, CENS
동일한 음악 작품의 다른 연주를 생각해보면, 모든 버전은 거의 동일한 음표 자료를 기반으로 한다. 동일한 멜로디가 동일한 화성의 맥락 내에서 재생된다.
음악 동기화 시나리오에서 보았듯이 크로마 기반 오디오 특징은 이러한 종류의 정보를 캡처하는 데 적합한 중간 수준(mid-level) 표현이다. 크로마 특징(feature)은 서양 음악 표기법에서 사용되는 12개의 피치 \(\mathrm{C}\), \(\mathrm{C}^\sharp\), \(\mathrm{D}\), \(\ldots\), \(\mathrm{B}\)에 기반하며, 각 크로마 벡터는 신호 프레임의 에너지가 12개의 크로마 밴드에 어떻게 분포되는지 나타낸다.
시간이 지남에 따라 이러한 분포를 측정하면 멜로디 및 화성 진행과 밀접하게 관련된 시간-크로마 표현(또는 크로마그램)이 생성된다. 이러한 진행은 종종 동일한 음악의 다른 녹음에 대해서도 유사하므로 크로마 특징을 오디오 매칭 또는 버전 식별과 같은 내용 기반 검색 작업에 적합한 도구로 사용한다.
크로마 특징을 계산하는 데는 다양한 방법이 있으며 로그 압축, 정규화 또는 스무딩과 같은 적절한 후처리 단계를 적용하여 크로마 특징의 속성을 조정할 수 있다.
- 이를 설명하기 위해 베토벤 교향곡 5번의 시작 부분에 대한 두 개의 다른 녹음을 살펴보자(여기서는 피아노로 줄인 악보로 표시됨). 한 공연(21초)은 번스타인이 지휘하고 다른 공연(18초)은 카라얀이 지휘한다.
- 코드 셀에서 \(10\mathrm{Hz}\)의 피쳐 레이트(feature rate)를 사용하여 Bernstein 및 Karajan 녹음에 대한 기본 크로마 변형을 생성한다. 여기서 각 크로마 벡터는 절반 크기의 윈도우 겹침이 있는 \(200~\mathrm{msec}\)의 윈도우에 해당한다.
ipd.display(Image(path_img+"FMP_C7_Audio_Beethoven_Op067-01-001-021_Sibelius-Piano.png", width=600))
def plot_two_chromagrams(C1, C2, Fs1=1, Fs2=1, title1='', title2='', figsize=(10, 2.5), clim=None):
plt.figure(figsize=figsize)
gs = gridspec.GridSpec(1, 2)
gs1 = gridspec.GridSpecFromSubplotSpec(1, 2, subplot_spec=gs[0], width_ratios=[1, 0.02], wspace=0.05)
gs2 = gridspec.GridSpecFromSubplotSpec(1, 2, subplot_spec=gs[1], width_ratios=[1, 0.02], wspace=0.05)
ax1, ax2, ax3, ax4 = plt.subplot(gs1[0]), plt.subplot(gs1[1]), plt.subplot(gs2[0]), plt.subplot(gs2[1])
plot_chromagram(C1, Fs1, ax=[ax1, ax2], clim=clim, title=title1)
plot_chromagram(C2, Fs2, ax=[ax3, ax4], clim=clim, title=title2)
plt.tight_layout()
plt.show()
fn_wav1 = 'FMP_C7_Audio_Beethoven_Op067-01-001-021_Bernstein.wav'
fn_wav2 = 'FMP_C7_Audio_Beethoven_Op067-01-001-021_Karajan.wav'
x1, Fs = librosa.load(path_data+fn_wav1)
x2, Fs = librosa.load(path_data+fn_wav2)
ipd.display(Audio(x1,rate=Fs))
ipd.display(Audio(x2,rate=Fs))
N = 4410
H = 2205
C1 = librosa.feature.chroma_stft(y=x1, sr=Fs, tuning=0, norm=None, hop_length=H, n_fft=N)
C2 = librosa.feature.chroma_stft(y=x2, sr=Fs, tuning=0, norm=None, hop_length=H, n_fft=N)
Fs1 = Fs / H
Fs2 = Fs / H
title1='Basic chromagram (Bernstein)'
title2='Basic chromagram (Karajan)'
plot_two_chromagrams(C1, C2, Fs1=Fs1, Fs2=Fs2, title1=title1, title2=title2)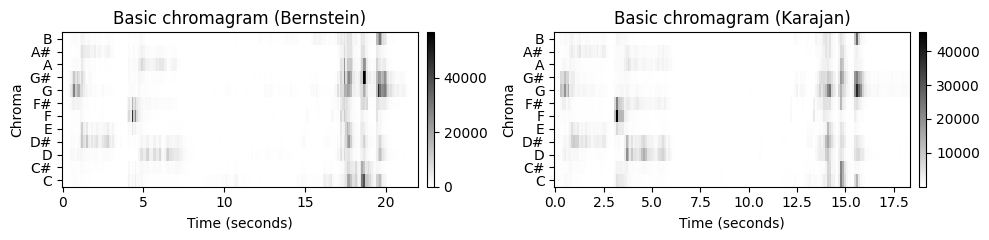
- 녹음의 다이내믹(dynamics)의 큰 차이를 균형 잡기 위해 정규화(normalization) 기술을 적용할 수 있다. 예를 들어, 유클리드 노름(\(\ell_2\)-norm)과 관련하여 각각의 크로마 벡터를 정규화할 수 있다. 이러한 정규화를 위해 두 가지 구현(
librosa.feature.chroma및normalize_feature_sequence)을 사용한다.
C1_norm_LR = librosa.feature.chroma_stft(y=x1, sr=Fs, tuning=0, norm=2, hop_length=H, n_fft=N) # norm=2
C2_norm_LR = librosa.feature.chroma_stft(y=x2, sr=Fs, tuning=0, norm=2, hop_length=H, n_fft=N)
title1 = r'$\ell_2$-normalized chromagram (Bernstein)'
title2 = r'$\ell_2$-normalized chromagram (Karajan)'
plot_two_chromagrams(C1_norm_LR, C2_norm_LR, Fs1=Fs1, Fs2=Fs2, title1=title1+' - librosa', title2=title2+' - librosa', clim=[0, 1])
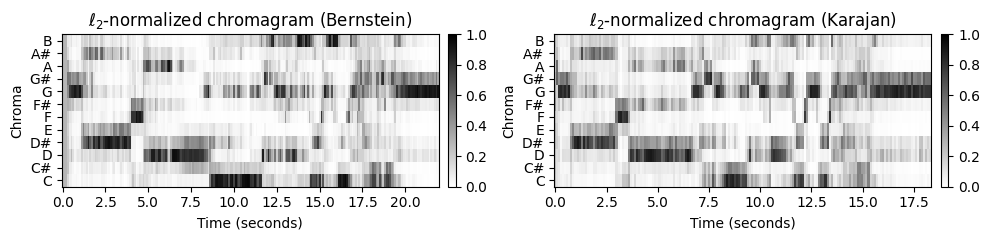
threshold = 0.0001
C1_norm = normalize_feature_sequence(C1, norm='2', threshold=threshold)
C2_norm = normalize_feature_sequence(C2, norm='2', threshold=threshold)
plot_two_chromagrams(C1_norm, C2_norm, Fs1=Fs1, Fs2=Fs2, title1=title1, title2=title2, clim=[0, 1])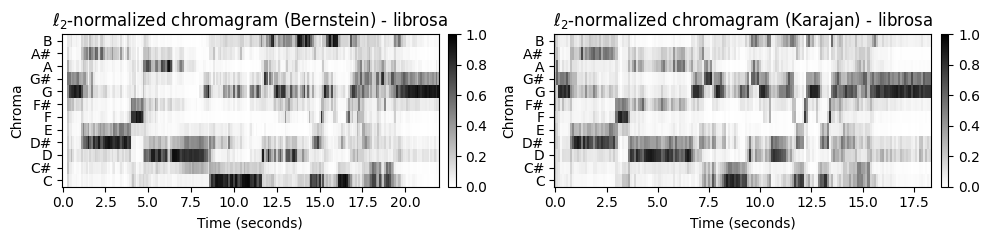
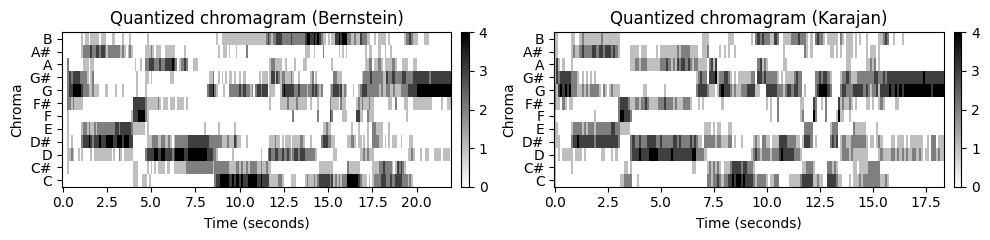
양자화 (Quantization)
이러한 정규화된 크로마그램 표현이 이미 두 녹음에서 유사한 패턴으로 나타나지만 여전히 성능별 차이가 많이 있다. 따라서 한 가지 아이디어는 추가 양자화(quantization) 및 스무딩 절차를 적용하여 로컬 템포, 아티큘레이션 및 음 실행의 변화로 인한 로컬 변동의 영향을 더 줄이는 것이다.
이제 이러한 단계가 실제로 구현될 수 있는 방법을 보여주는 구체적인 후처리 절차에 대해 논의한다. 위에서 계산한 기본 크로마 변형으로 시작하여 맨해튼 노름(\(\ell^1\)-norm)으로 각 크로마 벡터를 정규화하여 12개의 크로마 값을 더하면 1이 되게 한다.
\(X=(x_1,x_2,\ldots,x_N)\)는 정규화된 크로마 벡터 \(x_n\in[0,1]^{12}\), \(n\in[1:N]\)의 결과 시퀀스를 나타낸다고 하자. 이러한 각 벡터에는 0과 1 사이의 양수 항목만 있다. 다음으로 양자화(quantization) 함수 \(Q:[0,1]\to\{0,1,2,3,4\}\)를 다음과 같이 정의한다.
\[Q(a):=\left\{\begin{array}{llrcl} 0 & \text{ for } & 0 & \leq \,\, a\,\, < &0.05, \\ 1 & \text{ for } & 0.05 & \leq \,\, a\,\, < &0.1, \\ 2 & \text{ for } & 0.1 & \leq \,\, a\,\, < &0.2, \\ 3 & \text{ for } & 0.2 & \leq \,\, a\,\, < &0.4, \\ 4 & \text{ for } & 0.4 & \leq \,\, a\,\, \leq &1. \\ \end{array}\right.\]
첫 번째 단계에서 각 \(x_n\)의 구성 요소에 \(Q\)를 적용하여 각 크로마 벡터 \(x_n=(x_n(0),\ldots,x_n(11))^\top\in[0,1]^{12}\)를 양자화하여 다음을 산출한다. \[Q(x_n):=(Q(x_n(0)),\ldots,Q(x_n(11)))^\top.\]
직관적으로 이 양자화는 해당 크로마 클래스가 예를 들어 신호의 총 에너지의 \(40%\) 이상을 포함하는 경우 크로마 구성 요소에 \(4\)의 값을 할당한다. 또한 \(5%\) 임계값 미만의 크로마 구성 요소는 0으로 설정되어 노이즈에 대한 견고성을 높인다.
임계값은 소리 강도(intensity)의 로그 인식을 설명하기 위해 로그 방식으로 선택된다. 예를 들어 벡터 \(x_n=(0.02,0.5,0.3,0.07,0.11,0,\ldots,0)^\top\)은 벡터 \(Q(x_n):=(0,4,3,1,2,0,\ldots,0)^\top\)로 변환된다.
def quantize_matrix(C, quant_fct=None):
"""Quantize matrix values in a logarithmic manner (as done for CENS features)
Args:
C (np.ndarray): Input matrix
quant_fct (list): List specifying the quantization function (Default value = None)
Returns:
C_quant (np.ndarray): Output matrix
"""
C_quant = np.empty_like(C)
if quant_fct is None:
quant_fct = [(0.0, 0.05, 0), (0.05, 0.1, 1), (0.1, 0.2, 2), (0.2, 0.4, 3), (0.4, 1, 4)]
for min_val, max_val, target_val in quant_fct:
mask = np.logical_and(min_val <= C, C < max_val)
C_quant[mask] = target_val
return C_quantC1 = librosa.feature.chroma_stft(y=x1, sr=Fs, tuning=0, norm=1, hop_length=H, n_fft=N)
C2 = librosa.feature.chroma_stft(y=x2, sr=Fs, tuning=0, norm=1, hop_length=H, n_fft=N)
C1_Q = quantize_matrix(C1)
C2_Q = quantize_matrix(C2)
title1=r'$\ell_1$-normalized chromagram (Bernstein)'
title2=r'$\ell_1$-normalized chromagram (Karajan)'
plot_two_chromagrams(C1, C2, Fs1=Fs1, Fs2=Fs2, title1=title1, title2=title2, clim=[0, 1])
title1='Quantized chromagram (Bernstein)'
title2='Quantized chromagram (Karajan)'
plot_two_chromagrams(C1_Q, C2_Q, Fs1=Fs1, Fs2=Fs2, title1=title1, title2=title2, clim=[0, 4])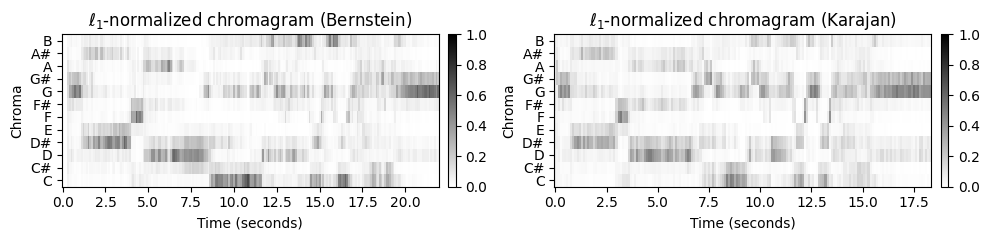
스무딩 및 다운샘플링 (Smoothing and Downsampling)
두 번째 단계에서 양자화된 시퀀스 \((Q(x_1),\ldots,Q(x_N))\)는 시간 차원을 따라 더욱 평활화(smoothed)된다.
이를 위해 스무딩 윈도우(smoothing window)(예: Hann window)의 길이를 결정하는 숫자 \(\ell\in\mathbb{N}\)를 고정한 다음, 시퀀스 \((Q(x_1),\ldots,Q(x_N))\)의 12개 구성 요소 각각의 로컬 평균(window 함수에 의해 가중됨)을 고려한다. 이는 다시 음수가 아닌 항목의 \(12\) 차원 벡터의 시퀀스를 생성한다.
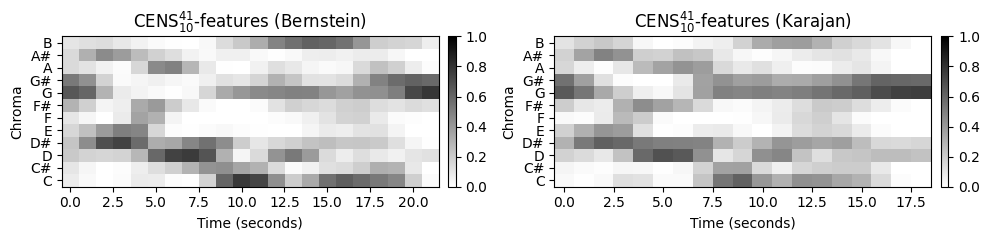
마지막 단계에서 이 시퀀스는 \(d\) 배만큼 다운샘플링되고 결과 벡터는 유클리드 노름(\(\ell^2\)-norm)에 따라 정규화된다. 양자화와 평활화의 두 단계는 \(\ell\) 연속 벡터의 윈도우에 대한 에너지 분포의 가중 통계를 계산하는 것으로 생각할 수 있다. 따라서 결과의 피쳐를 \(\mathrm{CENS}^{\ell}_{d}\) (chroma energy normalized statistics)라고 한다.
다음 코드 셀에서는 CENS 계산에 관련된 모든 단계를 요약하는 함수를 본다.
CENS 피쳐의 주요 아이디어는 상대적으로 큰 윈도우에 대한 통계를 통해 트릴이나 아르페지오와 같은 음 그룹의 템포, 아티큘레이션 및 실행에서 로컬 편차를 완화한다는 것이다.
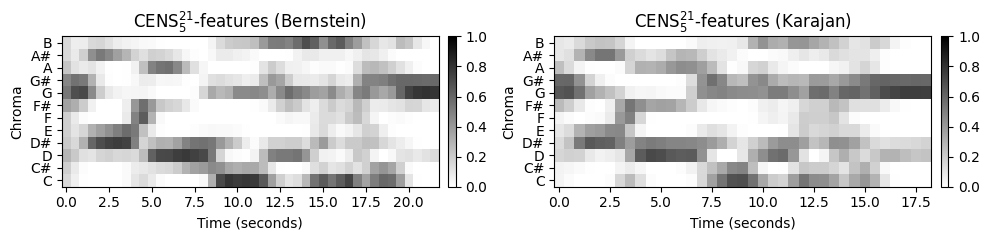
이 효과를 설명하기 위해 다음 예에서 두 베토벤 공연에 대한 \(\mathrm{CENS}^{41}_{10}\)-features의 시퀀스를 보여준다. 원래 크로마 시퀀스에 대한 피쳐 레이트 \(10~\mathrm{Hz}\)에서 시작하여, \(\ell=41\) 매개변수는 \(4100~\mathrm{msec}\)의 윈도우 크기에 해당한다. 또한 다운샘플링 매개변수 \(d=10\)를 사용하면 특징 속도가 \(1~\mathrm{Hz}\)(초당 하나의 기능)로 감소한다.
원본 크로마 시퀀스와 비교할 때, 두 공연의 결과 CENS 시퀀스는 훨씬 더 높은 수준의 유사성을 보유하면서도 일부 특징적인 음악 정보를 캡처한다.
def compute_cens_from_chromagram(C, Fs=1, ell=41, d=10, quant=True):
"""Compute CENS features from chromagram
Args:
C (np.ndarray): Input chromagram
Fs (scalar): Feature rate of chromagram (Default value = 1)
ell (int): Smoothing length (Default value = 41)
d (int): Downsampling factor (Default value = 10)
quant (bool): Apply quantization (Default value = True)
Returns:
C_CENS (np.ndarray): CENS features
Fs_CENS (scalar): Feature rate of CENS features
"""
C_norm = normalize_feature_sequence(C, norm='1')
C_Q = quantize_matrix(C_norm) if quant else C_norm
C_smooth, Fs_CENS = smooth_downsample_feature_sequence(C_Q, Fs, filt_len=ell,
down_sampling=d, w_type='hann')
C_CENS = normalize_feature_sequence(C_smooth, norm='2')
return C_CENS, Fs_CENSC1 = librosa.feature.chroma_stft(y=x1, sr=Fs, tuning=0, norm=1, hop_length=H, n_fft=N)
C2 = librosa.feature.chroma_stft(y=x2, sr=Fs, tuning=0, norm=1, hop_length=H, n_fft=N)
C1_CENS, Fs1_CENS = compute_cens_from_chromagram(C1, Fs1)
C2_CENS, Fs2_CENS = compute_cens_from_chromagram(C2, Fs2)
title1='CENS features (Bernstein)'
title2='CENS features (Karajan)'
plot_two_chromagrams(C1_CENS, C2_CENS, Fs1=Fs1_CENS, Fs2=Fs2_CENS, title1=title1, title2=title2, clim=[0, 1])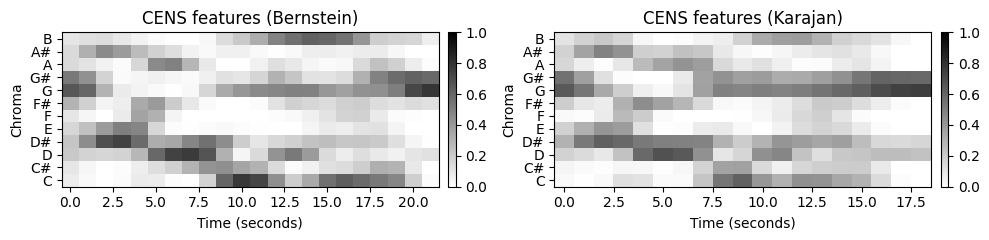
매개변수 설정
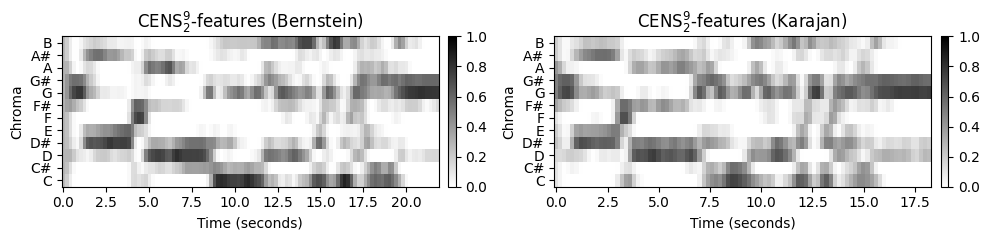
- CENS 개념은 두 가지 주요 매개변수 \(\ell\in\mathbb{N}\) 및 \(d\in\mathbb{N}\)에 따라 \(\mathrm{CENS}^{\ell}_{d}\) 크로마 특징 군을 생성한다. 설명된 절차는 원래 크로마그램의 비용 집약적인 계산을 반복하지 않고 특징 특이성(specificity)과 해상도(resolution)를 조정하는 계산이 간단한 방법을 소개한다. 다음 그림에서는 다양한 스무딩 및 다운샘플링 매개변수를 사용하는 CENS 특징 표현을 보여준다.
title1=r'$\ell_1$-normalized chromagram (Bernstein)'
title2=r'$\ell_1$-normalized chromagram (Karajan)'
plot_two_chromagrams(C1, C2, Fs1=Fs1, Fs2=Fs2, title1=title1, title2=title2, clim=[0, 1])
parameter_set = [(9, 2), (21, 5), (41, 10)]
for parameter in parameter_set:
ell = parameter[0]
d = parameter[1]
C1_CENS, Fs1_CENS = compute_cens_from_chromagram(C1, Fs1, ell=ell, d=d)
C2_CENS, Fs2_CENS = compute_cens_from_chromagram(C2, Fs2, ell=ell, d=d)
title1=r'CENS$^{%d}_{%d}$-features (Bernstein)' % (ell, d)
title2=r'CENS$^{%d}_{%d}$-features (Karajan)' % (ell, d)
plot_two_chromagrams(C1_CENS, C2_CENS, Fs1=Fs1_CENS, Fs2=Fs2_CENS,
title1=title1, title2=title2, clim=[0, 1])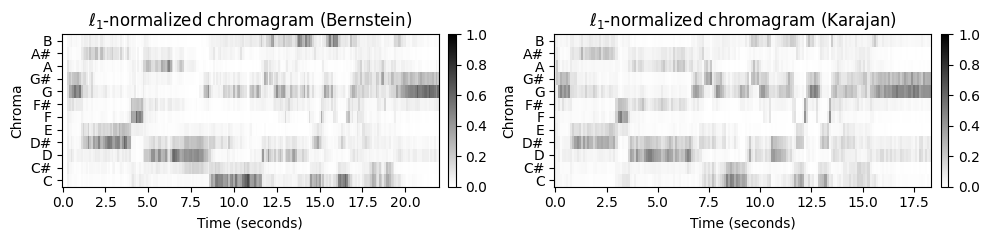
- CENS 피쳐는 어떤 크로마그램 표현으로도 시작하여 계산할 수 있다. 예를 들어 STFT 기반 크로마그램을 사용하는 대신 다중 속도 필터 뱅크(multirate filter bank)를 기반으로 하는 크로마그램으로 시작할 수 있다.
Image(path_img+"FMP_C7S3_CENS_WASPAA.png", width=700)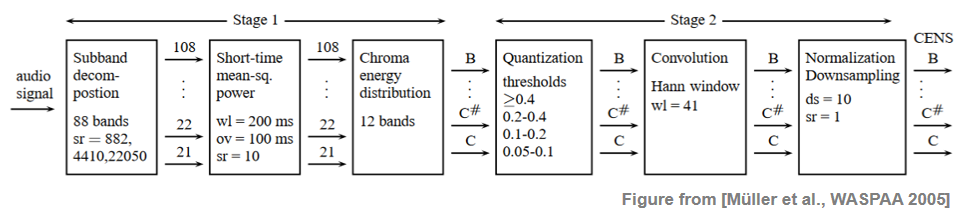
- 라이브러리 LibROSA에는 CENS 기능을 계산하는 함수(
librosa.feature.chroma_cens)도 포함되어 있다. 다운샘플링은 해당 함수 외부에서 수행되어야 한다(예:C_CENS[:, ::d]사용).
대각선 매칭 (Diagonal Matching)
매칭 함수 (Matching Function)
아래의 하위 시퀀스(subsequence) 매칭 기법은 오디오 매칭(audio matching) 작업을 동기로 한다. 오디오 매칭의 목표는 짧은 쿼리 오디오 클립에 음악적으로 해당하는 모든 오디오 발췌 부분을 검색하는 것이다.
추상적인 관점에서 \(X=(x_1,x_2,\ldots,x_N)\) 및 \(Y=(y_1,y_2,\ldots,y_M)\)를 쿼리 \(\mathcal{Q}\) 및 문서 \(\mathcal{D}\)를 각각 대표하는 두 개의 피처 시퀀스라고 하자. 쿼리의 길이 \(N\)는 일반적으로 데이터베이스 문서의 길이 \(M\)에 비해 짧다. 쿼리 \(\mathcal{Q}\)가 \(\mathcal{D}\)에 어떻게든 “포함”되어 있는지 확인하기 위해 시퀀스 \(X\)를 시퀀스 \(Y\)로 이동하고 \(X\)를 \(Y\)의 적절한 하위 시퀀스와 로컬에서 비교한다. 유사하거나 동등하게 \(X\)에 대한 작은 거리를 갖는 \(Y\)의 모든 하위 시퀀스는 쿼리에 대해 일치(match)하는 것으로 간주된다.
\(X\)를 \(Y\)의 하위 시퀀스와 로컬에서 비교하는 방법에는 여러 가지가 있다. 이제 대각선 매칭(diagonal matching)이라는 간단한 절차를 소개한다.
우선, 시퀀스 \(X\)와 \(Y\)의 크로마 벡터를 비교하기 위해 로컬 비용 측정(또는 로컬 거리 측정)을 고정해야 한다. 다음에서는 유클리드 노름과 관련하여 모든 특징이 정규화되었다고 가정하고 내적을 기반으로 거리 측정 \(c\)를 사용한다. \[c(x,y) = 1- \langle x,y\rangle = 1 - \sum_{k=1}^K x(k)y(k)\]
- 2개의 \(K\)차원 벡터 \(x\in\mathbb{R}^K\) 및 \(y\in\mathbb{R}^K\)
- \(\|x\|_2=\|y\|_2=1\)
- 또한, 모든 특징 벡터가 음이 아닌(nonnegative) 항목을 갖는다고 가정하면 \(c(x,y)\in[0,1]\)와 \(c(x,y)=0\)는 \(x=y\)일 때만 그렇다.
동일한 길이를 공유하는 두 개의 특징 시퀀스를 비교하는 한 가지 간단한 방법은 두 시퀀스의 해당 벡터 사이의 평균 거리를 계산하는 것이다. 이렇게 하면 쿼리 시퀀스 \(X=(x_1,\ldots,x_N)\)와 쿼리와 동일한 길이 \(N\)를 갖는 \(Y\)의 모든 하위 시퀀스 \((y_{1+m},\ldots,y_{N+m})\)를 비교할 수 있다. \(m\in[0:M-N]\)이 이동 인덱스를 나타낸다.
이 절차는 다음과 같이 정의된 매칭 함수 \(\Delta_\mathrm{Diag}:[0:M-N]\to\mathbb{R}\)를 생성한다. \[\Delta_\mathrm{Diag}(m) := \frac{1}{N}\sum_{n=1}^{N} c(x_n,y_{n+m})\]
이제 이 매칭 함수가 계산되는 방식을 약간 재구성한다. \(\mathbf{C}\in\mathbb{R}^{N\times M}\)가 다음과 같이 주어진 비용 매트릭스라고 하자. \[\mathbf{C}(n,m):=c(x_n,y_m)\] for \(n\in[1:N]\) and \(m\in[1:M]\)
그러면 다음 그림과 같이 \(\mathbf{C}\) 행렬의 대각선을 합산하여 \(\Delta_\mathrm{Diag}(m)\) 값을 얻는다(쿼리 길이에 의한 정규화까지). 이는 이 절차가 “대각선” 매칭으로 불리는 이유를 설명한다.
Image(path_img+"FMP_C7_F11.png", width=600)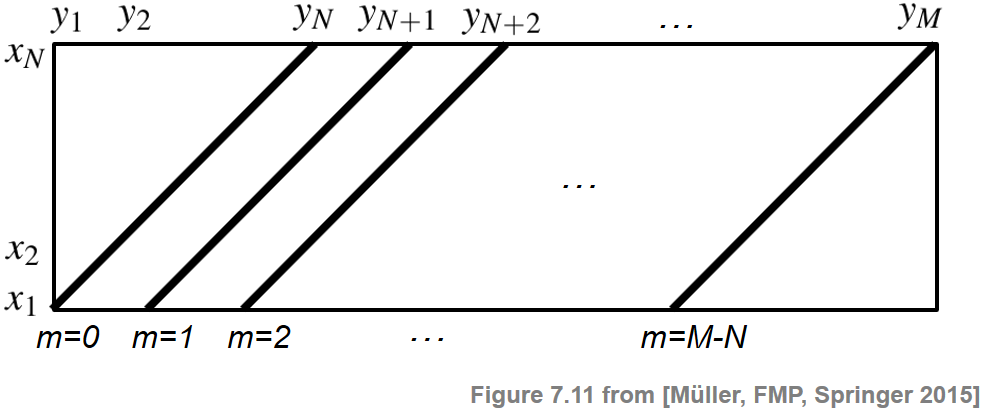
- 다음 코드 셀에서는 대각선 매칭 절차를 구현하고 생성한 합성 시퀀스 \(X\) 및 \(Y\)에 적용한다. 다음 예에서 시퀀스 \(Y\)는 \(X\)와 유사한 5개의 하위시퀀스를 포함한다(각각 위치 \(m=20\), \(40\), \(60\), \(80\), \(100\)에서 시작).
- \(m=20\)에서 시작하는 첫 번째 항목은 \(X\)의 정확한 복사본이다.
- \(m=40\) 및 \(m=60\)의 발생은 \(X\)의 노이즈 버전이다.
- \(m=80\)의 발생은 \(X\)의 확장된(느린) 버전이다.
- \(m=100\)의 발생은 \(X\)의 압축된(빠른) 버전이다.
- 다음 그림에서 볼 수 있듯이 매칭 함수 \(\Delta_\mathrm{Diag}\)는 예상 위치에서 로컬 최소값을 나타낸다. \(m=20\)의 첫 번째 최소값은 0이지만 \(m=40\) 및 \(m=60\)의 다음 두 최소값은 여전히 두드러진다(일치 값은 0에 가깝다). 그러나 늘림과 압축으로 인해 대각선 매칭 절차는 \(m=80\) 및 \(m=100\)에서 마지막 두 개의 하위시퀀스를 잘 캡처할 수 없다.
def scale_tempo_sequence(X, factor=1):
"""Scales a sequence (given as feature matrix) along time (second dimension)
Args:
X (np.ndarray): Feature sequences (given as K x N matrix)
factor (float): Scaling factor (resulting in length "round(factor * N)"") (Default value = 1)
Returns:
X_new (np.ndarray): Scaled feature sequence
N_new (int): Length of scaled feature sequence
"""
N = X.shape[1]
t = np.linspace(0, 1, num=N, endpoint=True)
N_new = np.round(factor * N).astype(int)
t_new = np.linspace(0, 1, num=N_new, endpoint=True)
X_new = scipy.interpolate.interp1d(t, X, axis=1)(t_new)
return X_new, N_new
def cost_matrix_dot(X, Y):
"""Computes cost matrix via dot product
Args:
X (np.ndarray): First sequence (K x N matrix)
Y (np.ndarray): Second sequence (K x M matrix)
Returns:
C (np.ndarray): Cost matrix
"""
return 1 - np.dot(X.T, Y)
def matching_function_diag(C, cyclic=False):
"""Computes diagonal matching function
Args:
C (np.ndarray): Cost matrix
cyclic (bool): If "True" then matching is done cyclically (Default value = False)
Returns:
Delta (np.ndarray): Matching function
"""
N, M = C.shape
assert N <= M, "N <= M is required"
Delta = C[0, :]
for n in range(1, N):
Delta = Delta + np.roll(C[n, :], -n)
Delta = Delta / N
if cyclic is False:
Delta[M-N+1:M] = np.inf
return Delta# Create snythetic example for sequences X and Y
N = 15
M = 130
feature_dim = 12
np.random.seed(2)
X = np.random.random((feature_dim, N))
Y = np.random.random((feature_dim, M))
Y[:, 20:20+N] = X
Y[:, 40:40+N] = X + 0.5 * np.random.random((feature_dim, N))
Y[:, 60:60+N] = X + 0.8 * np.random.random((feature_dim, N))
X_slow, N_slow = scale_tempo_sequence(X, factor=1.25)
Y[:, 80:80+N_slow] = X_slow
X_fast, N_fast = scale_tempo_sequence(X, factor=0.8)
Y[:, 100:100+N_fast] = X_fast
Y = librosa.util.normalize(Y, norm=2)
X = librosa.util.normalize(X, norm=2)
# Compute cost matrix and matching function
C = cost_matrix_dot(X, Y)
Delta = matching_function_diag(C)# Visualization
fig, ax = plt.subplots(2, 2, gridspec_kw={'width_ratios': [1, 0.02],
'height_ratios': [1, 1]}, figsize=(8, 4))
cmap = compressed_gray_cmap(alpha=-10, reverse=True)
plot_matrix(C, title='Cost matrix', xlabel='Time (samples)', ylabel='Time (samples)',
ax=[ax[0, 0], ax[0, 1]], colorbar=True, cmap=cmap)
plot_signal(Delta, ax=ax[1,0], xlabel='Time (samples)', ylabel='',
title = 'Matching function', color='k')
ax[1, 0].grid()
ax[1, 1].axis('off')
plt.tight_layout()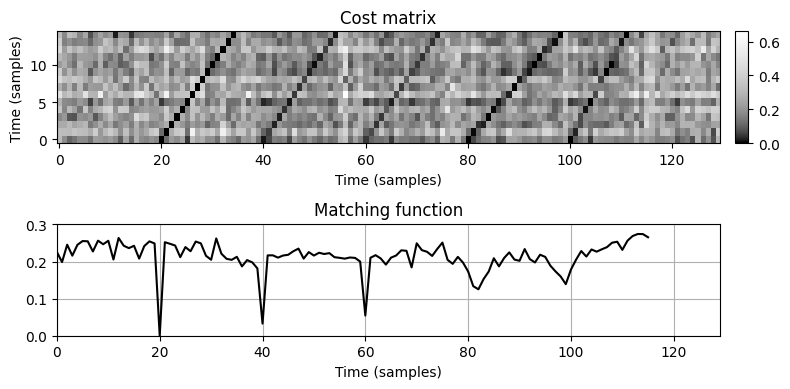
검색 절차 (Retrieval Procedure)
이제 쿼리 조각과 유사한 모든 일치 항목을 검색하기 위해 매칭 함수를 적용하는 방법에 대해 설명한다.
다음에서는 데이터베이스가 단일 문서 \(\mathcal{D}\)(예: 모든 문서 시퀀스 연결)로 표현된다고 가정한다. \(\mathcal{Q}\)와 \(\mathcal{D}\) 사이의 최상의 매칭을 결정하기 위해 매칭 함수 \(\Delta_\mathrm{Diag}\)를 최소화하는 인덱스 \(m^\ast\in[0:M-N]\)를 찾기만 하면 된다. \[m^\ast := \underset{m\in[0:M-N]}{\mathrm{argmin}} \,\,\Delta_\mathrm{Diag}(m)\]
최상의 일치는 다음의 하위시퀀스로 주어진다. \[Y(1+m^\ast:N+m^\ast) := (y_{1+m^\ast},\ldots,y_{N+m^\ast})\]
더 많은 일치 항목을 얻기 위해 가장 일치하는 이웃을 제외한다. 예를 들어, \(m\in [m^\ast-\rho:m^\ast+\rho]\cap [0:M-N]\)에 대해 \(\Delta_\mathrm{Diag}(m)=\infty\)를 설정하는 식으로 \(m^\ast\) 주변의 \(\rho= \lfloor N/2 \rfloor\) 이웃을 제외할 수 있다.
이렇게 하면 후속의 일치 항목이 쿼리 길이의 절반 이상 겹치지 않는다. 후속의 일치 항목을 찾기 위해 특정 수의 일치 항목을 얻거나 지정된 거리 임계값을 초과할 때까지 후자의 절차를 반복한다.
다음 코드 셀에서 이 검색 절차를 구현한다. \(\rho\) 매개변수 외에도 일치하는 값을 제한하기 위한 \(\tau\) 매개변수(즉, \(\Delta_\mathrm{Diag}(m^\ast)\leq \tau\)가 필요함)와 검색할 최대 일치 항목 수를 지정한다.
def mininma_from_matching_function(Delta, rho=2, tau=0.2, num=None):
"""Derives local minima positions of matching function in an iterative fashion
Args:
Delta (np.ndarray): Matching function
rho (int): Parameter to exclude neighborhood of a matching position for subsequent matches (Default value = 2)
tau (float): Threshold for maximum Delta value allowed for matches (Default value = 0.2)
num (int): Maximum number of matches (Default value = None)
Returns:
pos (np.ndarray): Array of local minima
"""
Delta_tmp = Delta.copy()
M = len(Delta)
pos = []
num_pos = 0
rho = int(rho)
if num is None:
num = M
while num_pos < num and np.sum(Delta_tmp < tau) > 0:
m = np.argmin(Delta_tmp)
pos.append(m)
num_pos += 1
Delta_tmp[max(0, m - rho):min(m + rho, M)] = np.inf
pos = np.array(pos).astype(int)
return pos
def matches_diag(pos, Delta_N):
"""Derives matches from positions in the case of diagonal matching
Args:
pos (np.ndarray or list): Starting positions of matches
Delta_N (int or np.ndarray or list): Length of match (a single number or a list of same length as Delta)
Returns:
matches (np.ndarray): Array containing matches (start, end)
"""
matches = np.zeros((len(pos), 2)).astype(int)
for k in range(len(pos)):
s = pos[k]
matches[k, 0] = s
if isinstance(Delta_N, int):
matches[k, 1] = s + Delta_N - 1
else:
matches[k, 1] = s + Delta_N[s] - 1
return matches
def plot_matches(ax, matches, Delta, Fs=1, alpha=0.2, color='r', s_marker='o', t_marker=''):
"""Plots matches into existing axis
Args:
ax: Axis
matches: Array of matches (start, end)
Delta: Matching function
Fs: Feature rate (Default value = 1)
alpha: Transparency pramaeter for match visualization (Default value = 0.2)
color: Color used to indicated matches (Default value = 'r')
s_marker: Marker used to indicate start of matches (Default value = 'o')
t_marker: Marker used to indicate end of matches (Default value = '')
"""
y_min, y_max = ax.get_ylim()
for (s, t) in matches:
ax.plot(s/Fs, Delta[s], color=color, marker=s_marker, linestyle='None')
ax.plot(t/Fs, Delta[t], color=color, marker=t_marker, linestyle='None')
rect = patches.Rectangle(((s-0.5)/Fs, y_min), (t-s+1)/Fs, y_max, facecolor=color, alpha=alpha)
ax.add_patch(rect)pos = mininma_from_matching_function(Delta, rho=N//2, tau=0.12, num=None)
matches = matches_diag(pos, N)
fig, ax, line = plot_signal(Delta, figsize=(8, 2), xlabel='Time (samples)',
title = 'Matching function with retrieved matches',
color='k')
ax.grid()
plot_matches(ax, matches, Delta)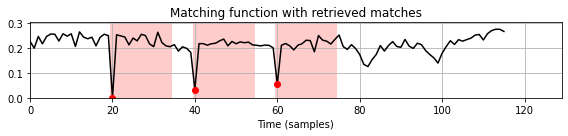
다중 쿼리를 이용한 매칭 함수 (Matching Function Using Multiple Queries)
- 이 기본적인 매칭 절차는 쿼리의 템포가 매칭할 구간 내 템포와 대략적으로 일치하는 경우에 잘 작동한다. 그러나 앞의 예에서도 알 수 있듯이 대각선 일치는 데이터베이스 하위시퀀스가 늘려지거나 압축된 버전의 쿼리일 때 문제가 된다. 이러한 템포 차이를 보완하기 위해 다중 쿼리 전략을 적용할 수 있다. 아이디어는 다음과 같다.
- 다양한 템포를 시뮬레이트하는 스케일링 작업을 적용하여 여러 버전의 쿼리를 생성한다.
- 대각선 매칭을 사용하여 스케일링된 각 버전에 대해 별도의 매칭 함수를 계산한다.
- 모든 결과 매칭 함수를 최소화하여 단일 매칭 함수를 생성한다.
- 이 아이디어는 SSM의 경로 구조를 향상시키기 위한 다중 필터링 접근 방식(multiple-filtering approach)과 유사하다. 다음 구현에서는 예상되는 상대 템포 차이의 범위를 샘플링하는 \(\Theta\) 집합을 도입한다. 음악 검색에서 일치하는 섹션 간의 상대적인 템포 차이가 \(50\)퍼센트보다 큰 경우는 거의 발생하지 않는다. 따라서 \(\Theta\)는 대략 \(-50\) ~ \(+50\) 퍼센트의 템포 변화를 커버하도록 선택할 수 있다. 예를 들어, 집합 \(\Theta=\{0.66,0.81,1.00,1.22,1.50\}\)(로그 간격의 템포 매개변수 포함)는 대략 \(−50\)에서 \(+50\) 퍼센트까지의 템포 변화를 포함한다. (이 집합은
compute_tempo_rel_set함수로 계산할 수 있다.)
def matching_function_diag_multiple(X, Y, tempo_rel_set=[1], cyclic=False):
"""Computes diagonal matching function using multiple query strategy
Args:
X (np.ndarray): First sequence (K x N matrix)
Y (np.ndarray): Second sequence (K x M matrix)
tempo_rel_set (np.ndarray): Set of relative tempo values (scaling) (Default value = [1])
cyclic (bool): If "True" then matching is done cyclically (Default value = False)
Returns:
Delta_min (np.ndarray): Matching function (obtained by from minimizing over several matching functions)
Delta_N (np.ndarray): Query length of best match for each time position
Delta_scale (np.ndarray): Set of matching functions (for each of the scaled versions of the query)
"""
M = Y.shape[1]
num_tempo = len(tempo_rel_set)
Delta_scale = np.zeros((num_tempo, M))
N_scale = np.zeros(num_tempo)
for k in range(num_tempo):
X_scale, N_scale[k] = scale_tempo_sequence(X, factor=tempo_rel_set[k])
C_scale = cost_matrix_dot(X_scale, Y)
Delta_scale[k, :] = matching_function_diag(C_scale, cyclic=cyclic)
Delta_min = np.min(Delta_scale, axis=0)
Delta_argmin = np.argmin(Delta_scale, axis=0)
Delta_N = N_scale[Delta_argmin]
return Delta_min, Delta_N, Delta_scaletempo_rel_set = [0.66, 0.81, 1.00, 1.22, 1.50]
color_set = ['b', 'c', 'gray', 'r', 'g']
num_tempo = len(tempo_rel_set)
Delta_min, Delta_N, Delta_scale = matching_function_diag_multiple(X, Y, tempo_rel_set=tempo_rel_set,
cyclic=False)
for k in range(num_tempo):
plot_signal(Delta_scale[k,:], figsize=(8, 2), xlabel='Time (samples)',
title = 'Matching function with scaling factor %.2f' % tempo_rel_set[k],
color=color_set[k], ylim=[0, 0.3])
plt.grid()
fig, ax, line = plot_signal(Delta_min, figsize=(8, 2), xlabel='Time (samples)',
title = 'Matching function', color='k', ylim=[0,0.3], linewidth=3, label='min')
ax.grid()
for k in range(num_tempo):
ax.plot(Delta_scale[k, :], linewidth=1, color=color_set[k], label=tempo_rel_set[k])
plt.legend(loc='lower right', framealpha=1);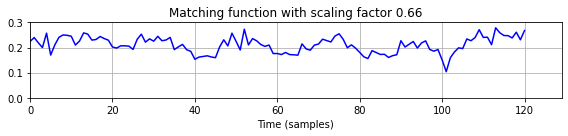

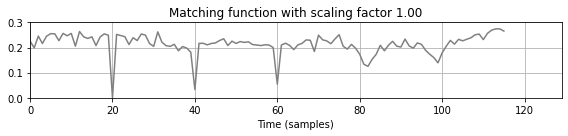
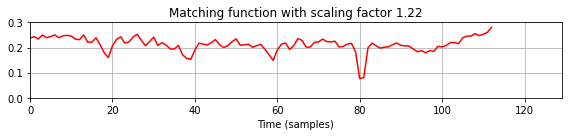
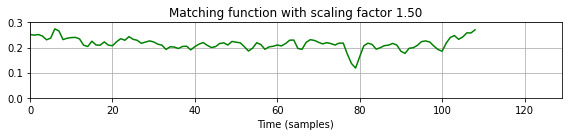
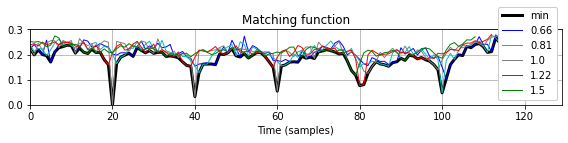
- 다중 쿼리 매칭 함수에서 확장되거나 압축된 쿼리 버전에 해당하는 하위시퀀스는 이제 값이 0에 훨씬 가까운 로컬 최소값으로 표시된다. 결과적으로, 위의 검색 절차(동일한 매개변수 설정 사용)는 이제 예상되는 일치 항목을 생성한다. 일치하는 하위 시퀀스의 길이는 고려된 모든 쿼리 버전에 대해 최소 일치 값을 생성하는 확장된 쿼리에서 파생된다. 따라서 아래 그림에서도 표시된 것처럼 길이는 원본(확장되지 않은) 쿼리의 길이 \(N\)과 다를 수 있다.
pos = mininma_from_matching_function(Delta_min, rho=N//2, tau=0.12, num=None)
matches = matches_diag(pos, Delta_N)
fig, ax = plt.subplots(2, 2, gridspec_kw={'width_ratios': [1, 0.02],
'height_ratios': [3, 3]}, figsize=(8, 4))
cmap = compressed_gray_cmap(alpha=-10, reverse=True)
plot_matrix(C, title='Cost matrix', xlabel='Time (samples)', ylabel='Time (samples)',
ax=[ax[0, 0], ax[0, 1]], colorbar=True, cmap=cmap)
plot_signal(Delta_min, ax=ax[1, 0], xlabel='Time (samples)',
title = 'Matching function with retrieved matches', color='k')
ax[1,0].grid()
plot_matches(ax[1, 0], matches, Delta_min)
ax[1,1].axis('off')
plt.tight_layout()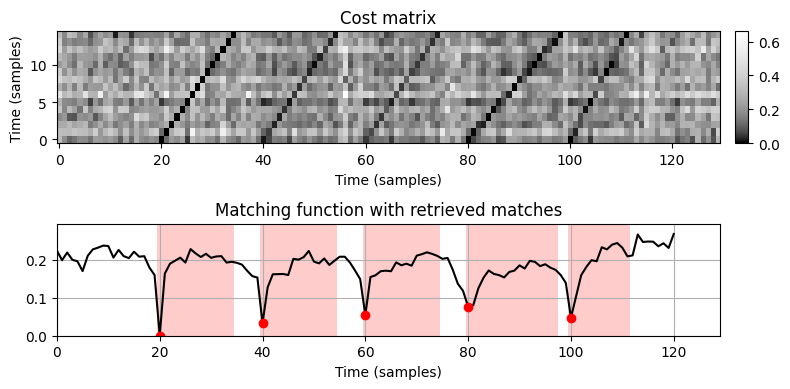
- 대각선 매칭에 대한 대안으로 동적 시간 워핑(DTW)의 변형을 사용하여 로컬 템포 변형을 처리할 수 있는 대안을 소개한다.
하위시퀀스 DTW
전역 정렬과 하위시퀀스 정렬
DTW(Dynamic Time Warping)에 대한 포스트에서 두 개의 특징 시퀀스를 비교할 때 템포 차이를 어떻게 처리할 수 있는지 연구한 바 있다. 워핑 경로의 개념을 기반으로 DTW 알고리즘을 사용하여 두 시퀀스 간의 최적 전역 정렬(global alignment)을 계산했다.
오디오 매칭 시나리오에서는 정렬 작업이 약간 다르다. 주어진 두 시퀀스 간의 전체 정렬을 찾는 대신 목표는 더 짧은 시퀀스에 최적으로 맞는 긴 시퀀스 내의 하위 시퀀스를 찾는 것이다.
Image(path_img+ "FMP_C7_F13+.png", width=800)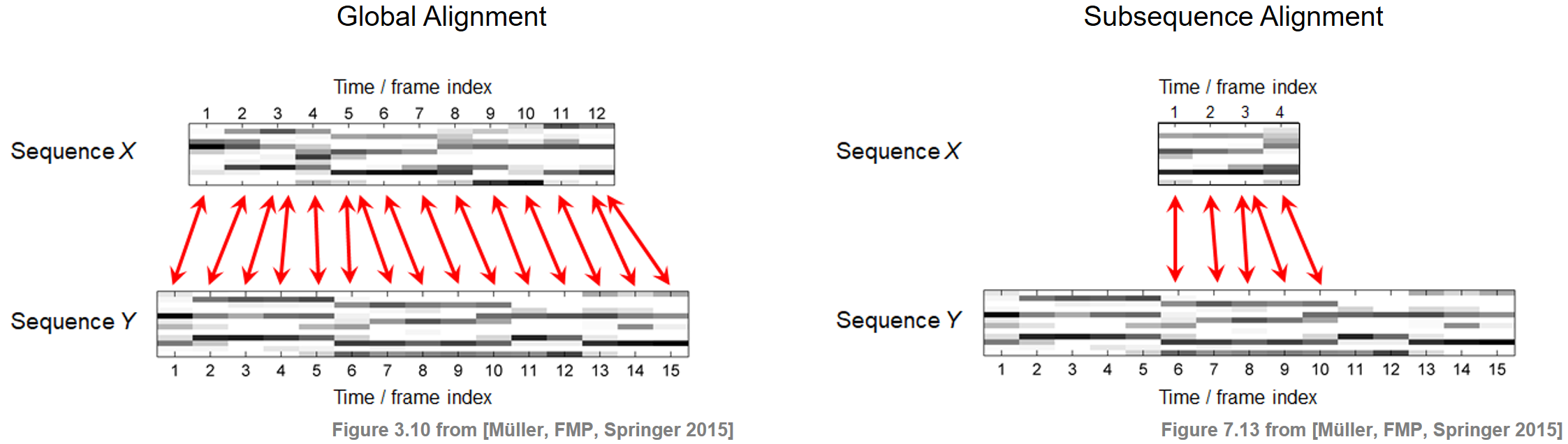
문제의 공식화
\(X=(x_1,x_2,\ldots,x_N)\) 및 \(Y=(y_1,y_2,\ldots,y_M)\)가 특징 공간 \(\mathcal{F}\)에 대한 두 개의 특징 시퀀스라고 가정하자. 길이 \(M\)는 길이 \(N\)보다 훨씬 크다. 또한, \(c:\mathcal{F}\times\mathcal{F}\to \mathbb{R}\)를 로컬 비용의 측정이라고 하고, \(\mathbf{C}\)를 \(\mathbf{C}(n,m)=c(x_n,y_m)\) (for \(n\in[1:N]\), \(m\in[1:M]\))로 주어진 결과 비용 행렬이라고 하자.
\(a,b\in[1:M]\)와 \(a\leq b\)의 두 인덱스에 대해, \(Y\)의 하위 시퀀스를 나타내는 다음 표기를 사용한다. \[Y(a:b):=(y_a,y_{a+1},\ldots,y_b)\]
전역 DTW 거리를 기반으로 매칭 문제는 다음과 같은 최적화 작업으로 공식화할 수 있다. \(X\)까지의 DTW 거리를 최소화하는 \(Y\)의 하위 시퀀스(\(Y\)의 모든 가능한 하위 시퀀스에서)를 찾는다. 즉, 다음에 의해 정의된 인덱스를 결정하는 것이다. \[(a^\ast,b^\ast) := \underset{(a,b): 1\leq a\leq b\leq M}{\mathrm{argmin}} \mathrm{DTW}\big( X\,,\, Y(a:b)\big).\]
하위시퀀스 DTW 알고리즘
\((a^\ast,b^\ast)\) 찾기에는 두 가지 종류의 최적화 단계가 포함된다.
- 먼저 \(Y\)의 모든 가능한 하위 시퀀스를 고려하여 최적의 하위 시퀀스를 찾아야 한다.
- 둘째, 각 하위시퀀스에 대해 \(X\)까지의 DTW 거리를 계산해야 하며, 여기에는 최적 워핑 경로의 비용을 결정하기 위한 최적화가 포함된다.
인덱스 \(a^\ast\) 및 \(b^\ast\)와 \(X\) 및 하위 시퀀스 \(Y(a^\ast:b^\ast)\) 사이의 모든 최적 정렬, 모두 단일 최적화 프레임워크 내에서 계산할 수 있다. 이를 위해 원래 DTW 알고리즘의 약간의 수정만 필요하다. 기본 아이디어는 \(X\)와의 정렬에서 \(Y\)의 시작과 끝에 생략을 허용하는 것이다.
원래 DTW 알고리즘과 마찬가지로 \(\mathbf{D}\)로 표시되는 \(N\times M\) 누적 비용 행렬을 정의한다. 이 행렬의 첫 번째 열은 다음과 같이 설정하여 초기화된다. \[\mathbf{D}(n,1):=\sum_{k=1}^{n} \mathbf{C}(k,1)\] for \(n\in [1:N]\).
그러나 \(\mathbf{D}\)의 첫 번째 행은 이제 다음과 같이 초기화된다. \[\mathbf{D}(1,m):= \mathbf{C}(1,m)\] for \(m\in [1:M]\).
이 초기화(initialization)는 비용을 누적하지 않고 시퀀스 \(Y\)의 모든 위치에서 시작할 수 있게 하여 \(X\)와 일치할 때 \(Y\)의 시작 부분을 건너뛸 수 있게 한다. \(\mathbf{D}\)의 나머지 값은 원래 DTW 알고리즘에서와 같이 재귀적으로 정의된다. \[\mathbf{D}(n,m) = \mathbf{C}(n,m) + \mathrm{min}\big\{ \mathbf{D}(n-1,m-1), \mathbf{D}(n-1,m), \mathbf{D}(n,m-1) \big\}\] for \(n\in[2:N]\) and \(m\in[2:M]\).
마지막으로, 전역 DTW 거리를 얻기 위해 계수 \(\mathbf{D}(N,M)\)만 보는 것이 아니라, 두 번째 수정은 전체 마지막 행 \(\mathbf{D}(N,m)\) (for \(m\in[1:M]\))을 고려하는 것이다. 이 행에서 인덱스 \(b^\ast\)는 다음과 같이 결정될 수 있다. \[b^\ast = \underset{b\in[1:M]}{\mathrm{argmin}} \,\,\mathbf{D}(N,b)\]
이 행에서 비용-최소화 인덱스를 선택하면(원래 DTW 접근 방식에서와 같이 마지막 인덱스를 사용하는 대신), \(X\)와 일치할 때 \(Y\)의 끝을 건너뛸 수 있게 한다.
시작 인덱스 \(a^\ast\)는 행렬 \(\mathbf{D}(N,m)\)에서 직접 읽을 수 없다. \(a^\ast\)를 결정하려면 고전적인 DTW에서와 같이 역추적(backtracking) 절차를 적용하여 최적의 워핑 경로를 구성해야 한다. 그러나 이번에는 (\(q_1=(N,M)\) 대신) \(q_1=(N,b^\ast)\)로 시작하고 \(\mathbf{D}\)의 첫 번째 행이 일부 요소 \(q_L=(1,m)\), \(m\in[1:M]\)(\(q_L=(1,1))\) 대신)에 도달하면 멈춘다. 인덱스 \(a^\ast\in[1:M]\)는 이 인덱스 \(m\)에 의해 결정된다. 또한 경로 \((q_L,q_{L-1},\ldots,q_1)\)는 시퀀스 \(X\)와 하위 시퀀스 \(Y(a^\ast:b^\ast)\) 사이의 최적 워핑 경로를 정의한다.
하위 시퀀스 DTW 알고리즘은 다음 표에 의해 구체화된다.
Image(path_img+"FMP_C7_E06.png", width=600)
- 이제 위에서 설명한 하위시퀀스 DTW 알고리즘을 구현한다. 실례로, 실수의 두 시퀀스와 차이의 절대값(1차원 유클리드 거리)을 비용 측정으로 간주한다. 즉, 피처 공간 \(\mathcal{F}=\mathbb{R}\) 및 \(c(x,y):=|x-y|\) for \(x,y\in \mathcal{F}\)가 있다.
X = np.array([3, 0, 6])
Y = np.array([2, 4, 0, 4, 0, 0, 5, 2])
N = len(X)
M = len(Y)
plt.figure(figsize=(6, 2))
plt.plot(X, c='k', label='$X$')
plt.plot(Y, c='b', label='$Y$')
plt.legend(loc='lower right')
plt.tight_layout()
plt.show()
print('Sequence X =', X)
print('Sequence Y =', Y)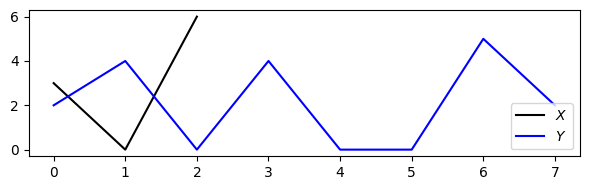
Sequence X = [3 0 6]
Sequence Y = [2 4 0 4 0 0 5 2]C = compute_cost_matrix(X, Y, metric='euclidean')
print('Cost matrix C =', C, sep='\n')Cost matrix C =
[[1. 1. 3. 1. 3. 3. 2. 1.]
[2. 4. 0. 4. 0. 0. 5. 2.]
[4. 2. 6. 2. 6. 6. 1. 4.]]- 다음으로 동적 프로그래밍을 사용하여 누적 비용 행렬 \(D\)와 \(D\)의 마지막 행에 있는 비용 최소화 인덱스 \(b^\ast\)를 계산한다.
def compute_accumulated_cost_matrix_subsequence_dtw(C):
"""Given the cost matrix, compute the accumulated cost matrix for
subsequence dynamic time warping with step sizes {(1, 0), (0, 1), (1, 1)}
Args:
C (np.ndarray): Cost matrix
Returns:
D (np.ndarray): Accumulated cost matrix
"""
N, M = C.shape
D = np.zeros((N, M))
D[:, 0] = np.cumsum(C[:, 0])
D[0, :] = C[0, :]
for n in range(1, N):
for m in range(1, M):
D[n, m] = C[n, m] + min(D[n-1, m], D[n, m-1], D[n-1, m-1])
return DD = compute_accumulated_cost_matrix_subsequence_dtw(C)
print('Accumulated cost matrix D =', D, sep='\n')
b_ast = D[-1, :].argmin()
print('b* =', b_ast)
print('Accumulated cost D[N, b*] = ', D[-1, b_ast])Accumulated cost matrix D =
[[1. 1. 3. 1. 3. 3. 2. 1.]
[3. 5. 1. 5. 1. 1. 6. 3.]
[7. 5. 7. 3. 7. 7. 2. 6.]]
b* = 6
Accumulated cost D[N, b*] = 2.0- 마지막으로 역추적을 사용하여 최적의 하위 시퀀스 \(Y(a^\ast:b^\ast)\)의 인덱스 \(a^\ast\)를 결정하는 최적 워핑 경로 \(P^\ast\)를 도출한다.
def compute_optimal_warping_path_subsequence_dtw(D, m=-1):
"""Given an accumulated cost matrix, compute the warping path for
subsequence dynamic time warping with step sizes {(1, 0), (0, 1), (1, 1)}
Args:
D (np.ndarray): Accumulated cost matrix
m (int): Index to start back tracking; if set to -1, optimal m is used (Default value = -1)
Returns:
P (np.ndarray): Optimal warping path (array of index pairs)
"""
N, M = D.shape
n = N - 1
if m < 0:
m = D[N - 1, :].argmin()
P = [(n, m)]
while n > 0:
if m == 0:
cell = (n - 1, 0)
else:
val = min(D[n-1, m-1], D[n-1, m], D[n, m-1])
if val == D[n-1, m-1]:
cell = (n-1, m-1)
elif val == D[n-1, m]:
cell = (n-1, m)
else:
cell = (n, m-1)
P.append(cell)
n, m = cell
P.reverse()
P = np.array(P)
return PP = compute_optimal_warping_path_subsequence_dtw(D)
print('Optimal warping path P =', P.tolist())
a_ast = P[0, 1]
b_ast = P[-1, 1]
print('a* =', a_ast)
print('b* =', b_ast)
print('Sequence X =', X)
print('Sequence Y =', Y)
print('Optimal subsequence Y(a*:b*) =', Y[a_ast:b_ast+1])
print('Accumulated cost D[N, b_ast]= ', D[-1, b_ast])Optimal warping path P = [[0, 3], [1, 4], [1, 5], [2, 6]]
a* = 3
b* = 6
Sequence X = [3 0 6]
Sequence Y = [2 4 0 4 0 0 5 2]
Optimal subsequence Y(a*:b*) = [4 0 0 5]
Accumulated cost D[N, b_ast]= 2.0- 최적의 워핑 경로(빨간색 점으로 표시됨)와 함께 하위시퀀스 DTW 방법의 비용 매트릭스 \(C\) 및 누적 비용 매트릭스 \(D\)를 시각화한다.
cmap = compressed_gray_cmap(alpha=-10, reverse=True)
plt.figure(figsize=(10, 1.8))
ax = plt.subplot(1, 2, 1)
plot_matrix_with_points(C, P, linestyle='-', ax=[ax], aspect='equal',
clim=[0, np.max(C)], cmap=cmap, title='$C$ with optimal warping path',
xlabel='Sequence Y', ylabel='Sequence X')
ax = plt.subplot(1, 2, 2)
plot_matrix_with_points(D, P, linestyle='-', ax=[ax], aspect='equal',
clim=[0, np.max(D)], cmap=cmap, title='$D$ with optimal warping path',
xlabel='Sequence Y', ylabel='Sequence X')
plt.tight_layout()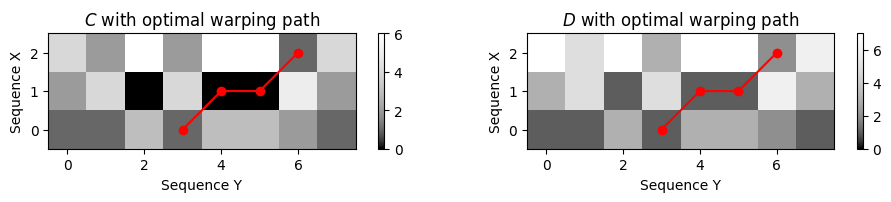
매칭 함수 (Matching Function)
최적 인덱스 \(b^\ast\)를 표시하는 것 외에도 \(\mathbf{D}\)의 마지막 행(아래 그림의 맨 위 행)은 더 많은 정보를 제공한다.
임의의 \(m\in[1:M]\)에 대한 각 항목 \(\mathbf{D}(N,m)\)은 위치 \(m\)에서 끝나는 최적의 하위 시퀀스 \(Y\)에 \(X\)를 정렬하는 총 비용을 나타낸다.
누적 비용을 쿼리의 \(N\) 길이로 정규화하는 다음의 설정을 통해 매칭 함수 \(\Delta_\mathrm{DTW}:[1:M]\to\mathbb{R}\)를 정의할 수 있다. \[\Delta_\mathrm{DTW}(m) := \frac{1}{N}\,\, \mathbf{D}(N,m)\] for \(m\in[1:M]\)
0에 가까운 \(\Delta_\mathrm{DTW}\)의 각 로컬 최소값 \(b\in[1:M]\)은 \(X\)로 DTW 거리가 작은 하위 시퀀스 \(Y(a:b)\)의 끝 위치를 나타낸다. 시작 인덱스 \(a\in[1:M]\), 그리고 이 하위시퀀스와 \(X\) 사이의 최적 정렬은 \(q_1=(N,b)\) 셀로 시작하는 역추적 절차를 통해 얻을 수 있다.
Delta = D[-1, :] / N
fig, ax = plt.subplots(2, 2, gridspec_kw={'width_ratios': [1, 0.02],
'height_ratios': [1, 1]}, figsize=(6, 4))
cmap = compressed_gray_cmap(alpha=-10, reverse=True)
plot_matrix(D, title=r'Accumulated cost matrix $\mathbf{D}$', xlabel='Time (samples)',
ylabel='Time (samples)', ax=[ax[0, 0], ax[0, 1]], colorbar=True, cmap=cmap)
rect = patches.Rectangle((-0.45, 1.48), len(Delta)-0.1, 1, linewidth=3, edgecolor='r', facecolor='none')
ax[0, 0].add_patch(rect)
plot_signal(Delta, ax=ax[1, 0], xlabel='Time (samples)', ylabel='', ylim=[0, np.max(Delta)+1],
title = r'Matching function $\Delta_\mathrm{DTW}$', color='k')
ax[1, 0].set_xlim([-0.5, len(Delta)-0.5])
ax[1, 0].grid()
ax[1, 1].axis('off')
plt.tight_layout()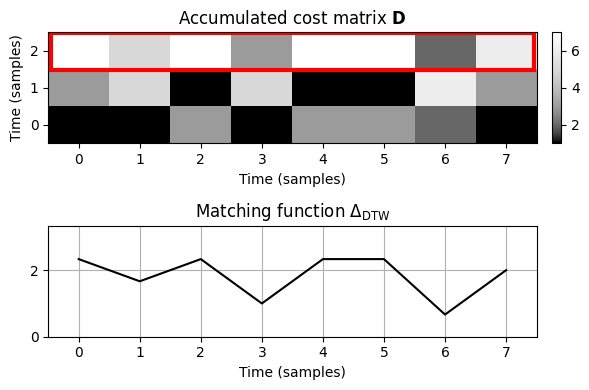
대각선 매칭과의 비교
- 하위시퀀스 DTW를 이용한 매칭함수 \(\Delta_\mathrm{DTW}\)는 대각선 매칭으로 얻은 매칭함수 \(\Delta_\mathrm{Diag}\)를 일종의 일반화한 것으로 볼 수 있다. 그러나 \(\Delta_\mathrm{Diag}\)와 \(\Delta_\mathrm{DTW}\) 사이에는 중요한 차이점이 있다.
- \(\Delta_\mathrm{Diag}\)는 일치하는 섹션의 시작 위치를 나타내지만 \(\Delta_\mathrm{DTW}\)는 일치하는 섹션의 끝 위치를 나타낸다. 간단히 말해서 대각선 매칭에서 \(X\) 쿼리는 정방향으로 처리되는 반면 DTW 기반 접근 방식에서는 역방향으로 처리된다.
- 또한 DTW 기반 접근 방식은 매칭 구간을 쿼리와 대각선으로 정렬하는 것이 아니라 매칭과 쿼리 사이의 시간적 편차를 처리할 수 있는 워핑(warping) 작업으로 처리한다.
- 이 효과는 쿼리 시퀀스 \(X\)의 길이가 \(N=3\)이고 가장 잘 일치하는 하위시퀀스 \(Y(3:6)\)의 길이가 \(4\)인 위의 실행 예제에서 확인 할 수 있다. DTW 기반 매칭 절차는 이러한 시간적 차이를 설명할 수 있다. 그러나 대각매칭을 사용하면 일치하는 서브시퀀스의 길이는 쿼리 \(X\)와 동일한 길이 \(N\)를 갖도록 강제된다. 이는 DTW 기반 매칭에서와 다른 최적의 하위 시퀀스로 이어진다.
N = len(X)
M = len(Y)
C = compute_cost_matrix(X, Y, metric='euclidean')
# Subsequence DTW
D = compute_accumulated_cost_matrix_subsequence_dtw(C)
Delta_DTW = D[-1, :] / N
P_DTW = compute_optimal_warping_path_subsequence_dtw(D)
a_ast = P[0, 1]
b_ast = P[-1, 1]
# Diagonal matching
Delta_Diag = matching_function_diag(C)
m = np.argmin(Delta_Diag)
P_Diag = []
for n in range(N):
P_Diag.append((n, m+n))
P_Diag = np.array(P_Diag)
matches_Diag = [(m, N)]# Visualization
fig, ax = plt.subplots(2, 4, gridspec_kw={'width_ratios': [1, 0.05, 1, 0.05],
'height_ratios': [1, 1]},
constrained_layout=True, figsize=(9, 4))
cmap = compressed_gray_cmap(alpha=-10, reverse=True)
plot_matrix_with_points(C, P_DTW, linestyle='-', ax=[ax[0, 0], ax[0, 1]],
clim=[0, np.max(C)], cmap=cmap, title='$C$ with optimal warping path',
xlabel='Sequence Y', ylabel='Sequence X')
plot_signal(Delta_DTW, ax=ax[1,0], xlabel='Time (samples)', ylabel='', ylim=[0, 5],
title=r'Matching function $\Delta_\mathrm{DTW}$', color='k')
ax[1, 0].set_xlim([-0.5, len(Delta)-0.5])
ax[1, 0].grid()
ax[1, 0].plot(b_ast, Delta_DTW[b_ast], 'ro')
ax[1, 0].add_patch(patches.Rectangle((a_ast-0.5, 0), b_ast-a_ast+1, 7, facecolor='r', alpha=0.2))
ax[1, 1].axis('off')
plot_matrix_with_points(C, P_Diag, linestyle='-', ax=[ax[0, 2], ax[0, 3]],
clim=[0, np.max(C)], cmap=cmap, title='$C$ with optimal diagonal path',
xlabel='Sequence Y', ylabel='Sequence X')
plot_signal(Delta_Diag, ax=ax[1, 2], xlabel='Time (samples)', ylabel='',
ylim=[0, 5], title = r'Matching function $\Delta_\mathrm{Diag}$', color='k')
ax[1, 2].set_xlim([-0.5, len(Delta)-0.5])
ax[1, 2].grid()
ax[1, 2].plot(m, Delta_Diag[m], 'ro')
ax[1, 2].add_patch(patches.Rectangle((m-0.5, 0), N, 7, facecolor='r', alpha=0.2))
ax[1, 3].axis('off');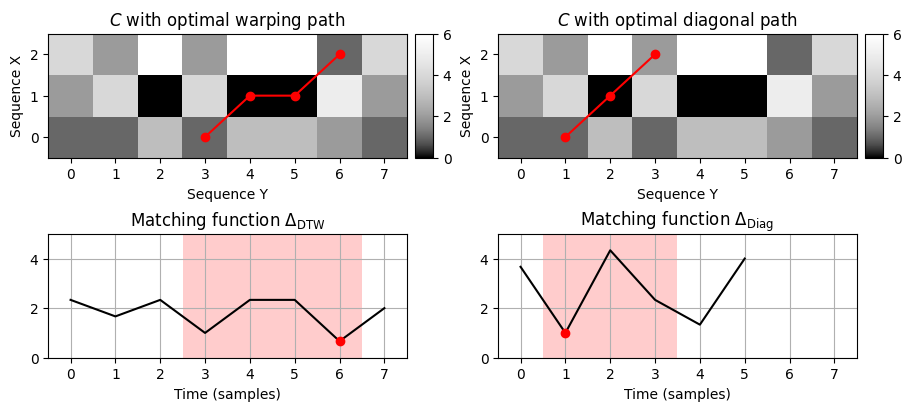
Step Size 조건
논의된 DTW의 하위 시퀀스 변형은 기존 DTW와 동일한 방식으로 수정될 수 있다. 특히, \(\Sigma=\{(1,0),(0,1),(1,1)\}\) 세트를 대체하여 단계 크기(step size) 조건을 변경할 수 있다. 예를 들어 \(\Sigma=\{(1,1)\}\) 세트를 사용하면 DTW 기반 매칭은 기본적으로 정방향 처리가 아닌 역방향 처리를 제외하고 대각선 매칭으로 축소된다. 일반적으로 \(\Sigma=\{(1,0),(0,1),(1,1)\}\) 세트를 사용하면 정렬 경로가 크게 저하될 수 있다. 극단적인 경우 \(X\) 시퀀스는 \(Y\)의 단일 요소에 할당될 수 있다.
따라서 특정 응용에서는 완전한 유연성을 갖춘 DTW 기반 매칭과 강한 대각선 매칭 사이의 타협점인 \(\Sigma=\{(2,1),(1,2),(1,1)\}\) 집합을 사용하는 것이 유리할 수 있다.
def compute_accumulated_cost_matrix_subsequence_dtw_21(C):
"""Given the cost matrix, compute the accumulated cost matrix for
subsequence dynamic time warping with step sizes {(1, 1), (2, 1), (1, 2)}
Args:
C (np.ndarray): Cost matrix
Returns:
D (np.ndarray): Accumulated cost matrix
"""
N, M = C.shape
D = np.zeros((N + 1, M + 2))
D[0:1, :] = np.inf
D[:, 0:2] = np.inf
D[1, 2:] = C[0, :]
for n in range(1, N):
for m in range(0, M):
if n == 0 and m == 0:
continue
D[n+1, m+2] = C[n, m] + min(D[n-1+1, m-1+2], D[n-2+1, m-1+2], D[n-1+1, m-2+2])
D = D[1:, 2:]
return D
def compute_optimal_warping_path_subsequence_dtw_21(D, m=-1):
"""Given an accumulated cost matrix, compute the warping path for
subsequence dynamic time warping with step sizes {(1, 1), (2, 1), (1, 2)}
Args:
D (np.ndarray): Accumulated cost matrix
m (int): Index to start back tracking; if set to -1, optimal m is used (Default value = -1)
Returns:
P (np.ndarray): Optimal warping path (array of index pairs)
"""
N, M = D.shape
n = N - 1
if m < 0:
m = D[N - 1, :].argmin()
P = [(n, m)]
while n > 0:
if m == 0:
cell = (n-1, 0)
else:
val = min(D[n-1, m-1], D[n-2, m-1], D[n-1, m-2])
if val == D[n-1, m-1]:
cell = (n-1, m-1)
elif val == D[n-2, m-1]:
cell = (n-2, m-1)
else:
cell = (n-1, m-2)
P.append(cell)
n, m = cell
P.reverse()
P = np.array(P)
return PC = compute_cost_matrix(X, Y, metric='euclidean')
D = compute_accumulated_cost_matrix_subsequence_dtw_21(C)
P = compute_optimal_warping_path_subsequence_dtw_21(D)
plt.figure(figsize=(9, 1.8))
ax = plt.subplot(1, 2, 1)
plot_matrix_with_points(C, P, linestyle='-', ax=[ax], aspect='equal',
clim=[0, np.max(C)], cmap=cmap, title='$C$ with optimal warping path',
xlabel='Sequence Y', ylabel='Sequence X')
ax = plt.subplot(1, 2, 2)
D_max = np.nanmax(D[D != np.inf])
plot_matrix_with_points(D, P, linestyle='-', ax=[ax], aspect='equal',
clim=[0, D_max], cmap=cmap, title='$D$ with optimal warping path',
xlabel='Sequence Y', ylabel='Sequence X')
for x, y in zip(*np.where(np.isinf(D))):
plt.text(y, x, '$\infty$', horizontalalignment='center', verticalalignment='center')
plt.tight_layout()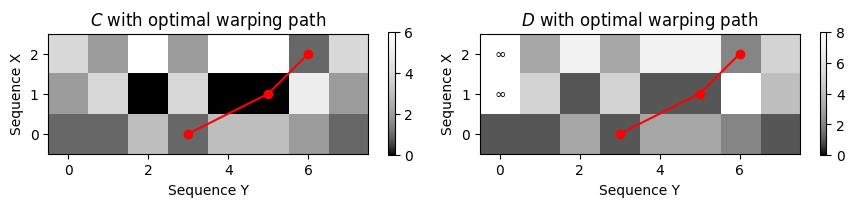
LibROSA 구현
LibROSA의 DTW 함수
librosa.sequence.dtw는 원본 DTW와 하위시퀀스 DTW를 모두 구현할 수 있다. 후자의 경우subseq=True매개변수를 설정해야 한다. 이 함수를 사용하면 로컬 가중치 및 전역 제약 조건과 같은 추가 매개변수뿐만 아니라 임의의 단계 크기 조건을 지정할 수 있다.다음에서는
librosa의 DTW 구현을 비교한다. 이를 위해 베토벤 교향곡 5번의 시작 부분을 살펴본다.- 쿼리는 처음 다섯 소절의 번스타인 녹음으로 구성된다.
- 데이터베이스 문서는 처음 21마디의 카라얀 버전으로 구성되어 있다.
- 매칭은 CENS-feature 시퀀스를 기반으로 수행된다.
def check_matrices(M1, M2, label='Matrices'):
if (M1.shape != M2.shape):
print(label, 'have different shape!', (M1.shape, M2.shape))
elif not np.allclose(M1, M2):
print(label, 'are numerical different!')
else:
print(label, 'are equal.') N_feat = 4410
H_feat = 2205
fn1 = 'FMP_C7_Audio_Beethoven_Op067-01-001-005_Bernstein.wav'
fn2 = 'FMP_C7_Audio_Beethoven_Op067-01-001-021_Karajan.wav'
x1, Fs = librosa.load(path_data+fn1)
x2, Fs = librosa.load(path_data+fn2)
C1 = librosa.feature.chroma_stft(y=x1, sr=Fs, tuning=0, norm=None, hop_length=H_feat, n_fft=N_feat)
C2 = librosa.feature.chroma_stft(y=x2, sr=Fs, tuning=0, norm=None, hop_length=H_feat, n_fft=N_feat)
ell = 21
d = 5
X, Fs_cens = compute_cens_from_chromagram(C1, ell=21, d=5)
Y, Fs_cens = compute_cens_from_chromagram(C2, ell=21, d=5)
N, M = X.shape[1], Y.shape[1]
C_FMP = compute_cost_matrix(X, Y, 'euclidean')
D_FMP = compute_accumulated_cost_matrix_subsequence_dtw(C_FMP)
P_FMP = compute_optimal_warping_path_subsequence_dtw(D_FMP)
sigma = np.array([[1, 0], [0, 1], [1, 1]])
D_librosa, P_librosa = librosa.sequence.dtw(C=C_FMP, step_sizes_sigma=sigma, subseq=True,
backtrack=True)
P_librosa = P_librosa[::-1, :]
check_matrices(D_librosa, D_FMP, 'D matrices')
check_matrices(P_librosa, P_FMP, 'Warping paths')
fig, ax = plt.subplots(2, 1, figsize=(9, 4))
title='LibROSA implementation with step size condition $\Sigma=\{(1, 0), (0, 1), (1, 1)\}$'
plot_matrix_with_points(D_librosa, P_librosa, ax=[ax[0]], cmap=cmap,
xlabel='Sequence Y (Karajan)', ylabel='Sequence X (Bernstein)',
title=title,
marker='o', linestyle='-')
title='libfmp implementation with step size condition $\Sigma=\{(1, 0), (0, 1), (1, 1)\}$'
plot_matrix_with_points(D_FMP, P_FMP, ax=[ax[1]], cmap=cmap,
xlabel='Sequence Y (Karajan)', ylabel='Sequence X (Bernstein)',
title=title,
marker='o', linestyle='-')
plt.tight_layout()D matrices are equal.
Warping paths are equal.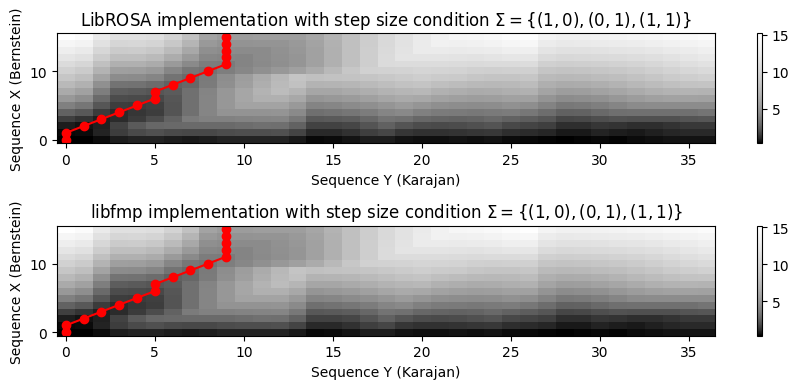
C_FMP = compute_cost_matrix(X, Y, 'euclidean')
D_FMP = compute_accumulated_cost_matrix_subsequence_dtw_21(C_FMP)
P_FMP = compute_optimal_warping_path_subsequence_dtw_21(D_FMP)
sigma = np.array([[2, 1], [1, 2], [1, 1]]) # 다른 step size 조건
D_librosa, P_librosa = librosa.sequence.dtw(C=C_FMP, step_sizes_sigma=sigma, subseq=True,
backtrack=True)
P_librosa = P_librosa[::-1, :]
check_matrices(D_librosa, D_FMP, 'D matrices')
check_matrices(P_librosa, P_FMP, 'Warping paths')
fig, ax = plt.subplots(2, 1, figsize=(9, 4))
title='LibROSA implementation with step size condition $\Sigma=\{(2, 1), (1, 2), (1, 1)\}$'
plot_matrix_with_points(D_librosa, P_librosa, ax=[ax[0]], cmap=cmap,
xlabel='Sequence Y (Karajan)', ylabel='Sequence X (Bernstein)',
title=title,
marker='o', linestyle='-')
title='libfmp implementation with step size condition $\Sigma=\{(2, 1), (1, 2), (1, 1)\}$'
plot_matrix_with_points(D_FMP, P_FMP, ax=[ax[1]], cmap=cmap,
xlabel='Sequence Y (Karajan)', ylabel='Sequence X (Bernstein)',
title=title,
marker='o', linestyle='-')
plt.tight_layout()D matrices are equal.
Warping paths are equal.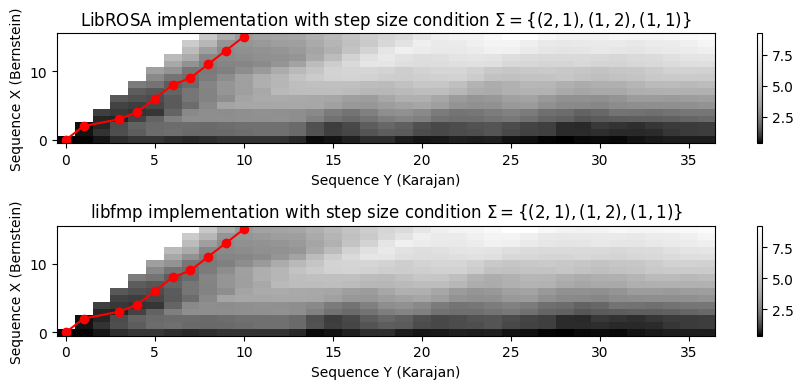
오디오 매칭: 전체 예시
전체 절차
오디오 매칭 시나리오에서 쿼리 오디오 조각 \(\mathcal{Q}\) 및 데이터베이스의 녹음 컬렉션이 주어진다. 일반성을 잃지 않고(예: 모든 녹음을 연결하여) 이 컬렉션이 단일 문서 \(\mathcal{D}\)로 표현된다고 가정한다.
일반적인 매칭 방식은 다음과 같은 방식으로 진행된다.
첫 번째 단계: 쿼리 \(\mathcal{Q}\) 및 문서 \(\mathcal{D}\)는 일련의 오디오 특징(features)으로 변환된다(예: 각각 \(X=(x_1,x_2,\ldots,x_N)\) 및 \(Y=(y_1,y_2,\ldots,y_M)\)). 쿼리 시퀀스의 길이 \(N\)는 일반적으로 데이터베이스 시퀀스의 길이 \(M\)보다 훨씬 짧다. 사용된 특징은 곡별 특성(예: 화성 및 멜로디 측면)을 캡처하는 동시에 연주별 변형(예: 로컬 템포, 아티큘레이션, 음표 실행 및 악기 연주)에 불변이어야 한다. 예를 들어 CENS 특징을 사용할 수 있다.
두 번째 단계: 특징 시퀀스 \(X\) 및 \(Y\)를 기반으로 \(X\)와 유사한 \(Y\)의 하위시퀀스를 식별하려고 시도한다. 이를 위해 DTW의 대각선 매칭 하위시퀀스 변형과 같은 기술을 사용할 수 있다. 두 경우 모두 매칭 곡선 \(\Delta:[0:M-1]\to\mathbb{R}\)를 얻는다. 0점에 가까운 \(\Delta\)의 모든 로컬 최소값의 위치는 \(X\)와 유사한 \(Y\)의 하위 시퀀스를 가리킨다.
세 번째 단계: \(\Delta\)의 로컬 최소값을 선택하기 위한 적절한 전략을 사용하여 매칭 절차의 결과를 구성하는 매칭 하위시퀀스(매치(mathces) 라고 함)의 순위 목록을 도출한다.
구현 예시
- 다음에서는 위에서 설명한 대로 오디오 매칭 절차의 구체적인 구현 예를 제공한다. 최종 결과에 상당한 영향을 미칠 수 있는 많은 대안(예: 특징 표현, 정렬 전략 및 최소 선택과 관련하여)과 다양한 매개변수 선택이 있다.
- 특징(feature) 표현으로
compute_cens_from_file함수로 계산된 CENS 특징을 사용한다. 특히 \(10~\mathrm{Hz}\)의 해상도를 가진 STFT 기반의 크로마 피처를 시작으로 해상도 \(2~\mathrm{Hz}\)의 \(\mathrm{CENS}^{21}_{5}\)-features를 사용한다. - 그런 다음 하위 시퀀스 DTW를 사용하여 매칭 함수를 계산한다. 구현에서는 단계 크기 조건 \(\Sigma=\{(2, 1), (1, 2), (1, 1)\}\)와 함께
compute_matching_function_dtw함수를 사용한다. - 매칭 전략은 위의 대각선 매칭에 설명된 간단한 반복 검색 절차를 따라 매칭 함수의 로컬 최소값을 식별한다. DTW의 경우 이러한 로컬 최소값은 일치하는 하위시퀀스의 끝 위치이다. 각 매치의 시작 위치를 얻으려면 최적의 워핑 경로(
compute_optimal_warping_path_subsequence_dtw_21)를 계산하기 위한 역추적 전략을 적용해야 한다.
- 특징(feature) 표현으로
def compute_cens_from_file(fn_wav, Fs=22050, N=4410, H=2205, ell=21, d=5):
"""Compute CENS features from file
Args:
fn_wav (str): Filename of wav file
Fs (scalar): Feature rate of wav file (Default value = 22050)
N (int): Window size for STFT (Default value = 4410)
H (int): Hop size for STFT (Default value = 2205)
ell (int): Smoothing length (Default value = 21)
d (int): Downsampling factor (Default value = 5)
Returns:
X_CENS (np.ndarray): CENS features
L (int): Length of CENS feature sequence
Fs_CENS (scalar): Feature rate of CENS features
x_duration (float): Duration (seconds) of wav file
"""
x, Fs = librosa.load(fn_wav, sr=Fs)
x_duration = x.shape[0] / Fs
X_chroma = librosa.feature.chroma_stft(y=x, sr=Fs, tuning=0, norm=None, hop_length=H, n_fft=N)
X_CENS, Fs_CENS = compute_cens_from_chromagram(X_chroma, Fs=Fs/H, ell=ell, d=d)
L = X_CENS.shape[1]
return X_CENS, L, Fs_CENS, x_duration
def compute_matching_function_dtw(X, Y, stepsize=2):
"""Compute CENS features from file
Args:
X (np.ndarray): Query feature sequence (given as K x N matrix)
Y (np.ndarray): Database feature sequence (given as K x M matrix)
stepsize (int): Parameter for step size condition (1 or 2) (Default value = 2)
Returns:
Delta (np.ndarray): DTW-based matching function
C (np.ndarray): Cost matrix
D (np.ndarray): Accumulated cost matrix
"""
C = cost_matrix_dot(X, Y)
if stepsize == 1:
D = compute_accumulated_cost_matrix_subsequence_dtw(C)
if stepsize == 2:
D = compute_accumulated_cost_matrix_subsequence_dtw_21(C)
N, M = C.shape
Delta = D[-1, :] / N
return Delta, C, D
def matches_dtw(pos, D, stepsize=2):
"""Derives matches from positions for DTW-based strategy
Args:
pos (np.ndarray): End positions of matches
D (np.ndarray): Accumulated cost matrix
stepsize (int): Parameter for step size condition (1 or 2) (Default value = 2)
Returns:
matches (np.ndarray): Array containing matches (start, end)
"""
matches = np.zeros((len(pos), 2)).astype(int)
for k in range(len(pos)):
t = pos[k]
matches[k, 1] = t
if stepsize == 1:
P = compute_optimal_warping_path_subsequence_dtw(D, m=t)
if stepsize == 2:
P = compute_optimal_warping_path_subsequence_dtw_21(D, m=t)
s = P[0, 1]
matches[k, 0] = s
return matches
def compute_plot_matching_function_DTW(fn_wav_X, fn_wav_Y, fn_ann,
ell=21, d=5, stepsize=2, tau=0.2, num=5, ylim=[0,0.35]):
ann, _ = read_structure_annotation(fn_ann)
color_ann = {'Theme': [0, 0, 1, 0.1], 'Match': [0, 0, 1, 0.2]}
X, N, Fs_X, x_duration = compute_cens_from_file(fn_wav_X, ell=ell, d=d)
Y, M, Fs_Y, y_duration = compute_cens_from_file(fn_wav_Y, ell=ell, d=d)
Delta, C, D = compute_matching_function_dtw(X, Y, stepsize=stepsize)
pos = mininma_from_matching_function(Delta, rho=2*N//3, tau=tau, num=num)
matches = matches_dtw(pos, D, stepsize=stepsize)
fig, ax = plt.subplots(2, 1, gridspec_kw={'width_ratios': [1],
'height_ratios': [1, 1]}, figsize=(8, 4))
cmap = compressed_gray_cmap(alpha=-10, reverse=True)
plot_matrix(C, Fs=Fs_X, ax=[ax[0]], ylabel='Time (seconds)',
title='Cost matrix $C$ with ground truth annotations (blue rectangles)',
colorbar=False, cmap=cmap)
plot_segments_overlay(ann, ax=ax[0], alpha=0.2, time_max=y_duration,
colors = color_ann, print_labels=False)
title = r'Matching function $\Delta_\mathrm{DTW}$ with matches (red rectangles)'
plot_signal(Delta, ax=ax[1], Fs=Fs_X, color='k', title=title, ylim=ylim)
ax[1].grid()
plot_matches(ax[1], matches, Delta, Fs=Fs_X, s_marker='', t_marker='o')
plt.tight_layout()
plt.show()베토벤 5번 교향곡
베토벤 예제에 대한 매칭 절차를 적용한다. 쿼리로 첫 번째 테마(첫 번째 \(21\) 소절)의 번스타인 녹음을 사용한다. 제시부의 반복과 요약에서 약간의 음악적 수정과 함께 테마가 다시 한 번 나타난다. 데이터베이스 문서에 관해서는 세 가지 다른 버전, 번스타인과 카라얀이 지휘한 오케스트라 버전 두 개와 셰르바코프가 연주한 리스트의 피아노 편곡 버전을 고려한다.
각 버전에 대해 비용 매트릭스 \(C\)를 테마에 대해 수동으로 주석이 달린 ground-truth 주석과 함께 시각화한다(버전당 3회 발생). 또한 상위 5개의 일치 항목과 결과의 매칭 함수를 보여준다
Image(path_img+"FMP_C7_Audio_Beethoven_Op067-01-001-021_Sibelius-Piano.png", width=700)
fn_wav_all = ['FMP_C7_Audio_Beethoven_Op067-01_Bernstein.wav',
'FMP_C7_Audio_Beethoven_Op067-01_Karajan.wav',
'FMP_C7_Audio_Beethoven_Op067-01_Scherbakov.wav']
fn_ann_all = ['FMP_C7_Audio_Beethoven_Op067-01_Bernstein_Theme.csv',
'FMP_C7_Audio_Beethoven_Op067-01_Karajan_Theme.csv',
'FMP_C7_Audio_Beethoven_Op067-01_Scherbakov_Theme.csv']
names_all = ['Bernstein', 'Karajan', 'Scherbakov (piano version)']
fn_wav_X = 'FMP_C7_Audio_Beethoven_Op067-01_Bernstein_Theme_1.wav'
print('--- QUERY: ---')
ipd.display(Audio(path_data+fn_wav_X))
print('--- DOCUMENTS: ---')
for i in range(3):
print(names_all[i])
#ipd.display(Audio(path_data+fn_wav_all[i])) # 용량 문제로 프린트 안함--- QUERY: ------ DOCUMENTS: ---
Bernstein
Karajan
Scherbakov (piano version)for f in range(3):
print('=== Query X: Bernstein (Theme 1); Database Y:', names_all[f],' ===')
compute_plot_matching_function_DTW(path_data+fn_wav_X, path_data+fn_wav_all[f], path_data+fn_ann_all[f])=== Query X: Bernstein (Theme 1); Database Y: Bernstein ===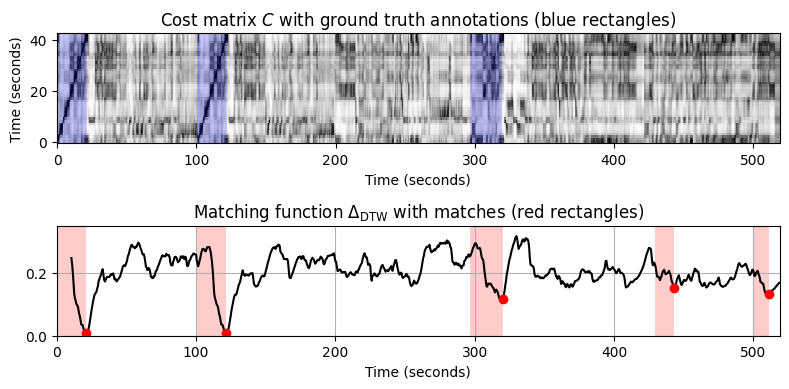
=== Query X: Bernstein (Theme 1); Database Y: Karajan ===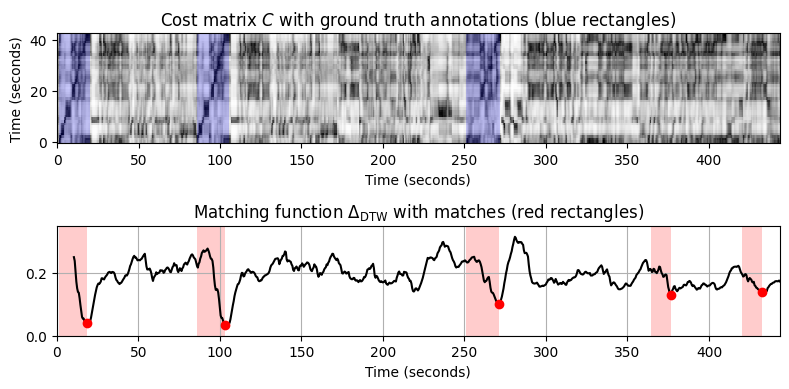
=== Query X: Bernstein (Theme 1); Database Y: Scherbakov (piano version) ===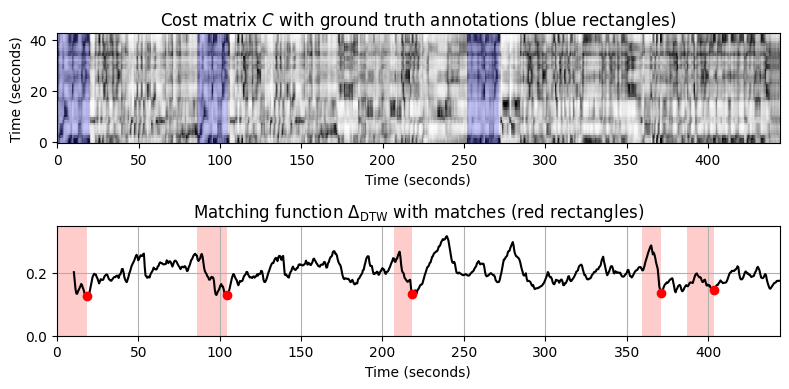
- 그림에서 다음과 같은 관찰을 할 수 있다.
- 매칭 함수는 세 가지 버전 모두에서 테마의 처음 두 발생을 명확하게 보여준다.
- 악기의 차이로 인해 Scherbakov 피아노 버전에서 Karajan 오케스트라 버전보다 Bernstein 오케스트라 쿼리를 식별하기가 훨씬 더 어렵다.
- 음악적 차이로 인해 제시부의 반복에서 주제의 두 번째 발생보다 요약에서 주제의 세 번째 발생을 식별하는 것이 훨씬 더 어렵다.
쇼스타코비치 예
두 번째 예로 쇼스타코비치의 Jazz Suite No.2 중 두 번째 왈츠를 들어보자. 이 곡은 \(A_1A_2BA_3A_4\) 형식으로, 여기서 \(A\) 부분은 \(38\) 소절로 구성되어 있으며 서로 다른 악기로 4번(\(A_1\), \(A_2\), \(A_3\) 및 \(A_4\) 부분) 나타난다. \(A_1\) 부분은 색소폰과 목악기로, \(A_2\) 부분은 현악기로, \(A_3\) 부분은 트롬본과 금관악기로, 마지막으로 \(A_4\) 부분은 투티 버전으로 멜로디를 연주한다.
쿼리 \(\mathcal{Q}\)로 Chailly 해석의 \(A_1\)의 \(16\)-measure 테마를 사용한다. 데이터베이스 문서로 Chailly 전체와 Yablonsky 전체 녹음을 각각 사용한다. 다음 그림에서는 위의 베토벤 예에서와 동일한 매칭 절차 및 매개 변수 설정을 사용한다.
fn_wav_all = ['FMP_C7_Audio_Shostakovich_Waltz-02_Chailly.wav',
'FMP_C7_Audio_Shostakovich_Waltz-02_Yablonsky.wav']
fn_ann_all = ['FMP_C7_Audio_Shostakovich_Waltz-02_Chailly_Theme.csv',
'FMP_C7_Audio_Shostakovich_Waltz-02_Yablonsky_Theme.csv']
names_all = ['Chailly', 'Yablonsky']
fn_wav_X = 'FMP_C7_Audio_Shostakovich_Waltz-02_Chailly_Theme_1.wav'
print('--- QUERY (saxophone, wood instrument): ---')
ipd.display(Audio(path_data+fn_wav_X))
print('--- DOCUMENTS: ---')
for i in range(2):
print(names_all[i])
#ipd.display(Audio(path_data+fn_wav_all[i])) # 용량 문제로 프린트 안함--- QUERY (saxophone, wood instrument): ------ DOCUMENTS: ---
Chailly
Yablonskyfor f in range(2):
print('=== Query X: Chailly (A1, 16 measures); Database Y:', names_all[f],' ===')
compute_plot_matching_function_DTW(path_data+fn_wav_X, path_data+fn_wav_all[f], path_data+fn_ann_all[f], ylim=[0, 0.25])=== Query X: Chailly (A1, 16 measures); Database Y: Chailly ===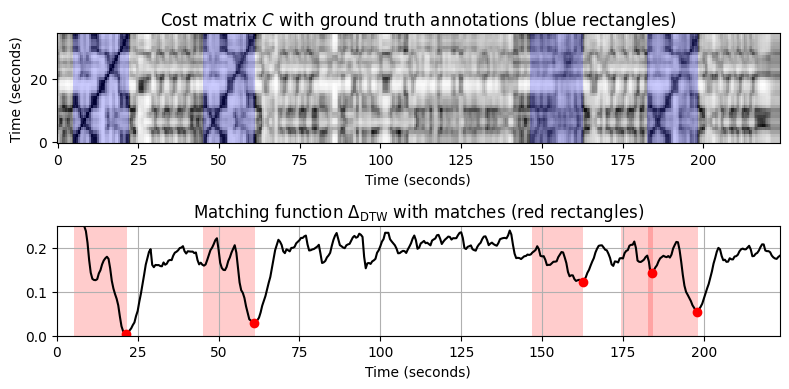
=== Query X: Chailly (A1, 16 measures); Database Y: Yablonsky ===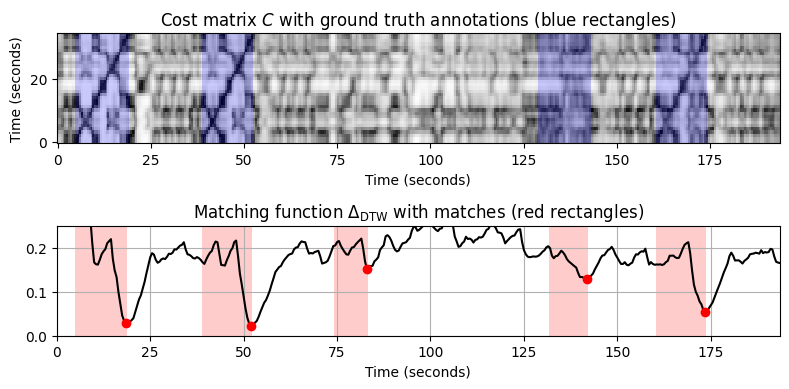
- 결과를 보면,
- 두 버전의 4개 항목은 각각 상위 4개 일치 항목으로 나타난다.
- Yablonsky 버전이 Chailly 버전보다 빠르지만 이러한 템포 변화는 DTW 기반 매칭 전략에 의해 성공적으로 처리된다.
- 두 버전 모두에서 \(A_3\)(트롬본 버전)의 발생이 가장 큰 \(\Delta_\mathrm{DTW}\) 거리를 가진다. 이는 저음 악기(예: 트롬본)의 스펙트럼이 일반적으로 진동 및 스미어링과 같은 현상을 나타내어 “잡음이 많은” CENS 특징을 초래한다는 사실 때문이다.
- 매칭 절차의 한계를 나타내기 위해 다음으로 \(\mathcal{Q}\) 쿼리로 \(A_3\)(트롬본 버전)의 첫 번째 \(16\) 소절을 사용하고 실험을 반복한다. Yablonsky 버전의 \(A_3\) 테마는 올바르게 식별할 수 있었지만 이제 나머지 항목을 식별하기가 훨씬 더 어려워졌다. 결과적으로 false-positive 및 false-negative 매칭이 증가한다.
fn_wav_X = 'FMP_C7_Audio_Shostakovich_Waltz-02_Chailly_Theme_3.wav'
print('--- QUERY (trombone): ---')
ipd.display(Audio(path_data+fn_wav_X))--- QUERY (trombone): ---for f in range(2):
print('=== Query X: Chailly (A3, 16 measures); Database Y:',names_all[f],' ===')
compute_plot_matching_function_DTW(path_data+fn_wav_X, path_data+fn_wav_all[f], path_data+fn_ann_all[f], ylim=[0,0.25])=== Query X: Chailly (A3, 16 measures); Database Y: Chailly ===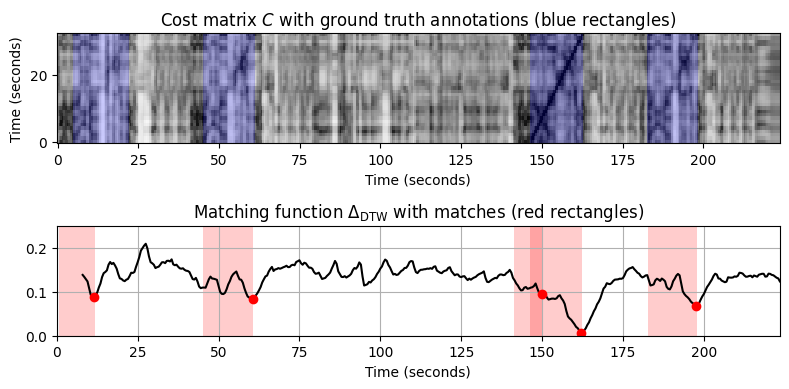
=== Query X: Chailly (A3, 16 measures); Database Y: Yablonsky ===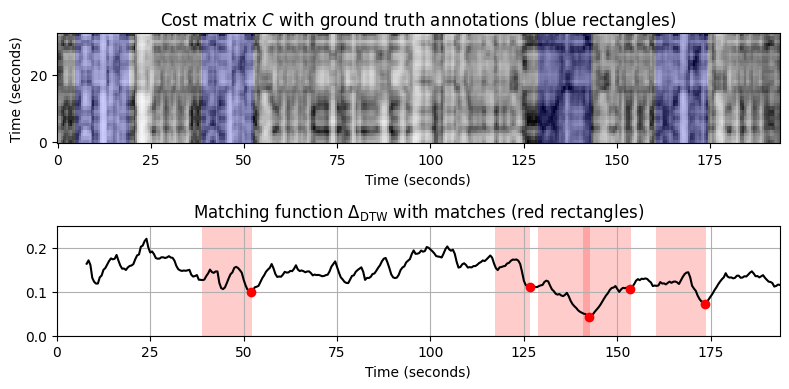
- 매칭 결과의 품질은 또한 쿼리 길이에 따라 결정적으로 달라진다. 짧은 기간의 쿼리는 일반적으로 낮은 특이성으로 인해 가짜 일치가 많이 발생하는 반면, 쿼리 길이를 늘려 특이성을 높이면 일반적으로 일치하는 횟수가 줄어든다.
- \(\mathcal{Q}\) 쿼리로 Chailly 기록의 \(A_3\)의 \(32\) measures(\(16\) 대신)을 고려하여 이를 설명한다.
fn_wav_X = 'FMP_C7_Audio_Shostakovich_Waltz-02_Chailly_Theme_3_32.wav'
fn_ann_all = ['FMP_C7_Audio_Shostakovich_Waltz-02_Chailly_Theme_32.csv',
'FMP_C7_Audio_Shostakovich_Waltz-02_Yablonsky_Theme_32.csv']
print('--- QUERY (trombone - 32 measures): ---')
ipd.display(Audio(path_data+fn_wav_X))--- QUERY (trombone - 32 measures): ---for f in range(2):
print('=== Query X: Chailly (A3, 32 measures); Database Y:',names_all[f],' ===')
compute_plot_matching_function_DTW(path_data+fn_wav_X, path_data+fn_wav_all[f], path_data+fn_ann_all[f], ylim=[0, 0.2])=== Query X: Chailly (A3, 32 measures); Database Y: Chailly ===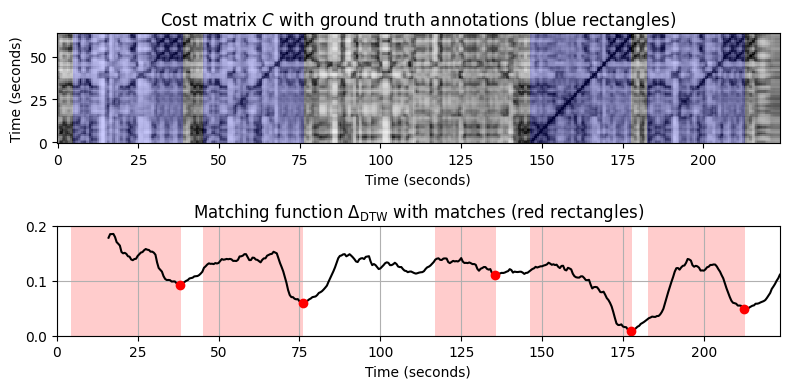
=== Query X: Chailly (A3, 32 measures); Database Y: Yablonsky ===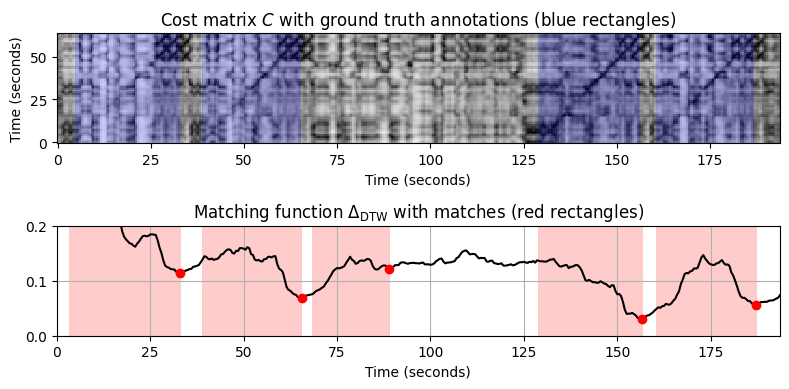
조옮김 불변 매칭 함수 (transposition-invariant matching function)
- 검색 응용에서 오디오 발췌 부분이 다른 음악 키로 재생되더라도 식별할 수 있어야 되는 경우가 있다. 이제 쿼리와 일치하는 데이터베이스 섹션 간에 가능한 조옮김를 처리하는 방법에 대해 설명한다.
- 예를 들어 Zager와 Evans의 “In the Year 2525”라는 노래를 생각해 보자(5.music structure에서 다룸). 이 노래는 \(IV_1V_2V_3V_4V_5V_6V_7BV_8O\)의 전체적인 음악적 구조를 가지고 있다. \(I\) 부분으로 표현되는 느린 인트로로 시작하며 \(V\) 부분으로 표현되는 노래의 절은 8번 나온다. 처음 4개의 벌스 섹션은 동일한 음악 키에 있지만 \(V_5\) 및 \(V_6\)는 위쪽으로 1반음 조옮김되고 \(V_7\) 및 \(V_8\)는 위쪽으로 2개 반음 조옮김된다.
Image("../img/5.music_structure_analysis/FMP_C4_F13_ZagerEvans_InTheYear2525.png", width=600)
\(12\)차원 크로마 축을 따라 크로마 특징을 순환적으로 이동하여 조옮김 시뮬레이션을 한다.
- cyclic shift operator \(\rho:\mathbb{R}^{12} \to \mathbb{R}^{12}\):
- \(\rho(x):=(x(11),x(0),x(1),\ldots,x(10))^\top\)
- for \(x=(x(0),x(1),\ldots,x(10),x(11))^\top\in\mathbb{R}^{12}\).
- cyclic shift operator \(\rho:\mathbb{R}^{12} \to \mathbb{R}^{12}\):
\(\rho\)를 연속적으로 적용하면 \(i\in[0:11]\)에 대한 12개의 서로 다른 순환 이동 \(\rho^i\)를 얻을 수 있다. 또한 \(\rho^i(X)=(\rho^i(x_1),\rho^i(x_2),\ldots,\rho^i(x_N))\)를 \(i\in[0:11]\)에 대한 쿼리 \(X\)라고 하자. 그런 다음 12개의 시퀀스 \(\rho^i(X)\) 각각을 별도의 쿼리로 사용하여 데이터베이스에서 매칭 항목을 검색한다. 이를 위해 먼저 각 \(\rho^i(X)\) 및 \(Y\)에 대해 \(\Delta^{i}\)와 같은 별도의 매칭 함수를 계산한다.
조옮김 불변 매칭 함수(transposition-invariant matching function) \(\Delta^\mathrm{TI}\)는 다음을 설정하여 얻는다. \[\Delta^\mathrm{TI}(m):= \min_{i\in [0:11]} \Delta^{i}(m)\] for \(m\in[0:M-1]\).
이제 Zager와 Evans의 노래 “In the Year 2525”를 통해 첫 절 섹션 \(V_1\)을 쿼리 \(X\)로 사용하고, 전체 노래를 데이터베이스 시퀀스 \(Y\)로 사용한다. 이전과 같이 DTW 기반 매칭 접근 방식에 대해 동일한 구현을 사용한다. \(\Delta^{0}=\Delta_\mathrm{DTW}\)이다. 시각화에서는 \(i=0,1,2,3\)에 대한 매칭 함수 \(\Delta^{i}\)와 조옮김 불변 일치 함수 \(\Delta^\mathrm{TI}\)를 보여준다. 처음 8개의 로컬 최소값 \(\Delta^\mathrm{TI}\)는 8개의 절 섹션의 끝 위치를 올바르게 나타낸다.
def compute_matching_function_dtw_ti(X, Y, cyc=np.arange(12), stepsize=2):
"""Compute transposition-invariant matching function
Args:
X (np.ndarray): Query feature sequence (given as K x N matrix)
Y (np.ndarray): Database feature sequence (given as K x M matrix)
cyc (np.nda(rray): Set of cyclic shift indices to be considered (Default value = np.arange(12))
stepsize (int): Parameter for step size condition (1 or 2) (Default value = 2)
Returns:
Delta_TI (np.ndarray): Transposition-invariant matching function
Delta_ind (np.ndarray): Cost-minimizing indices
Delta_cyc (np.ndarray): Array containing all matching functions
"""
M = Y.shape[1]
num_cyc = len(cyc)
Delta_cyc = np.zeros((num_cyc, M))
for k in range(num_cyc):
X_cyc = np.roll(X, k, axis=0)
Delta_cyc[k, :], C, D = compute_matching_function_dtw(X_cyc, Y, stepsize=stepsize)
Delta_TI = np.min(Delta_cyc, axis=0)
Delta_ind = np.argmin(Delta_cyc, axis=0)
return Delta_TI, Delta_ind, Delta_cycfn_wav = 'FMP_C4_F13_ZagerEvans_InTheYear2525.wav'
fn_ann = 'FMP_C4_F13_ZagerEvans_InTheYear2525.csv'
fn_wav_X = 'FMP_C7_Audio_ZagerEvans_InTheYear2525_Part-V1.wav'
#ipd.display(Audio(path_data+fn_wav))ann, _ = read_structure_annotation(path_data+fn_ann)
ann_color = {'I': 'white', 'V1': 'red', 'V2': 'red', 'V3': 'red', 'V4': 'red', 'V5': 'green', 'V6': 'green',
'V7': 'blue', 'B': 'white', 'V8': 'blue', 'O': 'gray', '': 'white'}
X, N, Fs_X, x_duration = compute_cens_from_file(path_data+fn_wav_X, ell=21, d=5)
Y, M, Fs_Y, y_duration = compute_cens_from_file(path_data+fn_wav, ell=21, d=5)
Delta_TI, Delta_ind, Delta_cyc = compute_matching_function_dtw_ti(X, Y)
pos = mininma_from_matching_function(Delta_TI, rho=2*N//3, tau=0.1, num=8)fig, ax = plt.subplots(6, 1, figsize=(7, 8), gridspec_kw={'height_ratios': [1, 1, 1, 1, 1, 0.25]})
color_set = ['red', 'green', 'blue', 'gray', 'gray', 'gray', 'gray', 'gray', 'gray', 'gray', 'gray', 'gray']
for k in range(4):
plot_signal(Delta_cyc[k,:], ax=ax[k], xlabel='', ylabel = r'$\Delta^{%d}$' % k,
color=color_set[k], ylim=[0, 0.3])
ax[k].grid()
for k in range(12):
plot_signal(Delta_cyc[k,:], ax=ax[4], color=color_set[k], ylim=[0, 0.3])
plot_signal(Delta_TI, ax=ax[4], color='k', linewidth='3', ylim=[0, 0.3],
ylabel = r'$\Delta^{\mathrm{TI}}$', xlabel='')
ax[4].grid()
plot_segments(ann, ax=ax[5], nontime_axis=False, adjust_nontime_axislim=False,
colors=ann_color, alpha=0.25)
ax[4].plot(pos, Delta_TI[pos], 'ro')
ax[5].set_xlabel('Time (seconds)')
plt.tight_layout()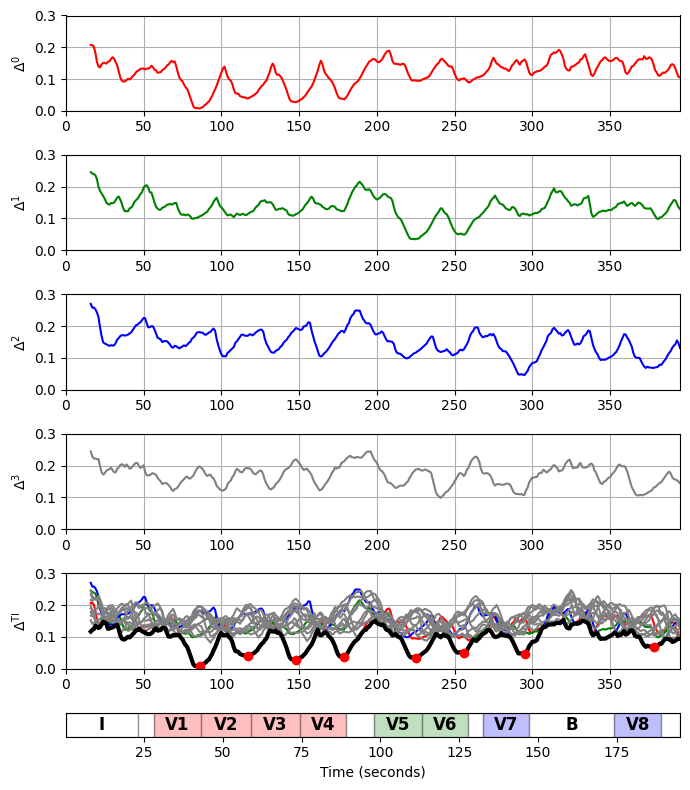
출처:
- https://www.audiolabs-erlangen.de/resources/MIR/FMP/C7/C7S2_CENS.html
- https://www.audiolabs-erlangen.de/resources/MIR/FMP/C7/C7S2_DiagonalMatching.html
- https://www.audiolabs-erlangen.de/resources/MIR/FMP/C7/C7S2_SubsequenceDTW.html
- https://www.audiolabs-erlangen.de/resources/MIR/FMP/C7/C7S2_AudioMatching.html
\(\leftarrow\) 8.2. 오디오 식별