자기 상관성: AR 모델은 시계열 데이터의 자기 상관성을 모델링한다. 즉, 현재의 값이 과거의 값들과 어떻게 연관되어 있는지를 분석한다.
정상성(Stationarity): AR 모델을 적용하기 위해서는 시계열 데이터가 정상 시계열이어야 한다. 즉, 시계열의 평균과 분산이 시간에 따라 일정해야 하며, 공분산이 두 시점 간의 간격에만 의존해야 한다. 비정상 시계열은 차분(differencing)과 같은 방법으로 정상화할 수 있다.
모델 선택: AR 모델의 차수 \(p\)는 중요한 선택 요소이다. 너무 낮은 차수는 데이터의 구조를 충분히 설명하지 못할 수 있고, 너무 높은 차수는 과적합(overfitting)을 초래할 수 있다. AIC(Akaike Information Criterion)나 BIC(Bayesian Information Criterion) 같은 정보 기준을 사용하여 최적의 차수를 결정할 수 있다.
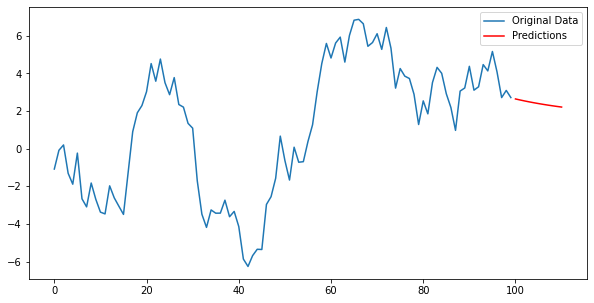
import numpy as npimport pandas as pdfrom statsmodels.tsa.ar_model import AutoRegimport matplotlib.pyplot as plt# 임의의 시계열 데이터 생성np.random.seed(123)data = pd.Series(np.random.randn(100).cumsum())# AR 모델 적합 (여기서는 차수 p=2로 설정)model = AutoReg(data, lags=2)model_fitted = model.fit()# 모델 파라미터 출력print(model_fitted.params)# 예측predictions = model_fitted.predict(start=len(data), end=len(data)+10)plt.figure(figsize=(10,5))plt.plot(data, label='Original Data')plt.plot(np.arange(len(data), len(data)+11), predictions, label='Predictions', color='red')plt.legend()plt.show()
MA(Moving Average) 모델은 시계열 분석에서 사용되는 또 다른 중요한 모델이다. 이 모델은 시계열 데이터의 현재 값이 과거의 예측 오차들의 선형 조합으로 표현될 수 있다고 가정한다. MA 모델은 시계열의 불규칙적인 변동(잡음)을 모델링하는 데 특히 유용하다.
과거의 예측 오차: MA 모델은 현재의 값이 과거의 예측 오차들에 의해 영향을 받는다고 가정한다. 이는 AR 모델과 대비되는 부분으로, AR 모델은 과거의 값들에 의해 현재 값이 결정된다고 보는 것이다.
잡음의 필터링: MA 모델은 시계열 데이터에서 잡음을 분리해내는 필터 역할을 할 수 있다. 이는 시계열 데이터의 중요한 구조적 정보를 추출하는 데 도움을 준다.
차수의 결정: MA 모델의 차수 \(q\)는 중요한 선택 요소다. 차수가 너무 낮으면 데이터의 구조를 충분히 설명하지 못할 수 있고, 너무 높으면 모델이 과적합될 위험이 있다.
정상성을 나타내는 어떤 AR(p) 모델을 MA(\(\infty\)) 모델로 쓸 수 있으며, MA(q) 모델을 AR(\(\infty\)) process로 쓸 수 있다. 이를 가역적(invertible)이라고 한다.
\(|\theta|<1\)이면, 가중치의 시차(lag) 값이 증가함에 따라 증가하고, 따라서 더 멀리 떨어진 관측값일 수록 현재 오차에 미치는 영향이 커진다.
\(|\theta|=1\)이면, 가중치가 크기에 대해 상수이고, 멀리 떨어진 관측값과 가까운 관측값 모두 같은 영향을 미친다.
\(|\theta|<1\)일 때, 과정은 가역적(invertible)이다.
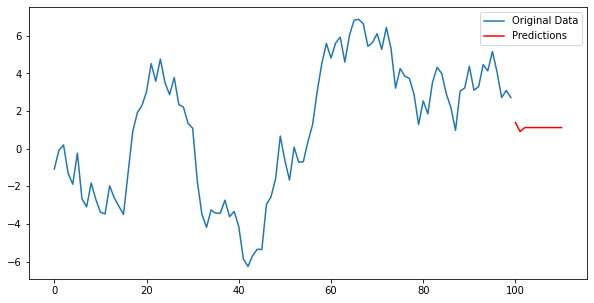
from statsmodels.tsa.arima.model import ARIMA# MA 모델 적합 (여기서는 차수 q=2로 설정)model = ARIMA(data, order=(0, 0, 2)) # ARIMA 모델에서 AR 부분을 0으로 설정하여 순수한 MA 모델을 생성model_fitted = model.fit()# 모델 파라미터 출력print(model_fitted.summary())# 예측predictions = model_fitted.predict(start=len(data), end=len(data)+10)plt.figure(figsize=(10,5))plt.plot(data, label='Original Data')plt.plot(np.arange(len(data), len(data)+11), predictions, label='Predictions', color='red')plt.legend()plt.show()
\(X_{t} = c + \epsilon_{t} + \theta \epsilon_{t-1}\)
\(E[X_{t}] = c\)
\(Var[X_{t}] = (1+\theta^{2})\sigma^{2}\)
\(Cov(X_{t},X_{t-1}) = \theta\sigma^{2}\)
\(Cov(X_{t},X_{t-k}) = 0\) for k > 1
MA(1) process는 추가적인 가정이 없이도 약정상성을 만족
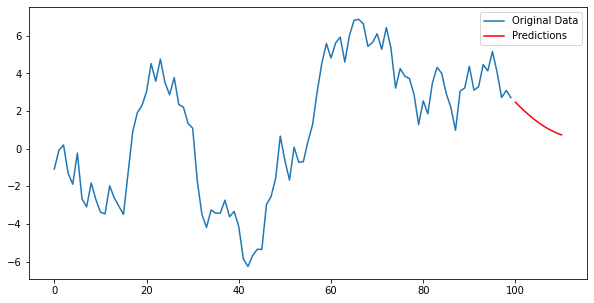
ARMA Model
ARMA(Autoregressive Moving Average)은 자기 회귀(AR) 모델과 이동 평균(MA) 모델을 결합한 형태다. ARMA 모델은 시계열 데이터의 자기 상관성과 불규칙적인 변동을 모두 캡처할 수 있기 때문에, 비교적 복잡한 시계열 데이터를 모델링할 때 널리 사용된다.
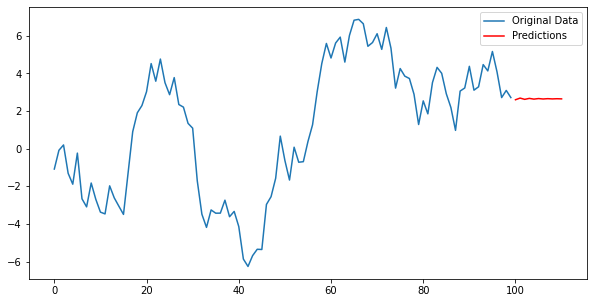
ARIMA(Autoregressive Integrated Moving Average)는 시계열 데이터의 비정상성을 처리하기 위해 고안된 모델이다. ARIMA는 ARMA 모델을 확장한 것으로, ARMA가 정상 시계열에만 적용 가능한 반면, ARIMA는 비정상 시계열 데이터에도 적용할 수 있다는 장점이 있다.
비정상 시계열 데이터 적용 가능: 차분을 통해 비정상 시계열을 정상 시계열로 변환한 후, ARMA 모델을 적용한다.
예측력: ARIMA 모델은 미래 값의 예측에 자주 사용되며, 금융, 경제, 사회 과학 등 다양한 분야에서 활용된다.
모델 차수의 결정: AIC, BIC와 같은 정보 기준을 사용하여 최적의 \(p,d,q\) 값을 결정한다.
C:\Users\master\anaconda3\envs\py38\lib\site-packages\statsmodels\tsa\statespace\representation.py:374: FutureWarning: Unknown keyword arguments: dict_keys(['typ']).Passing unknown keyword arguments will raise a TypeError beginning in version 0.15.
warnings.warn(msg, FutureWarning)
차수 결정
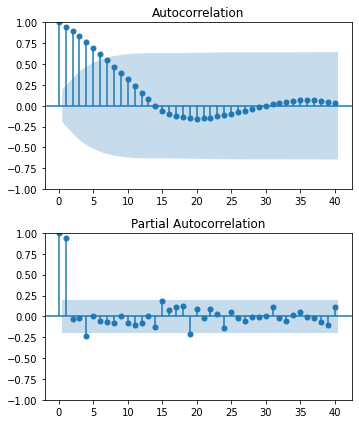
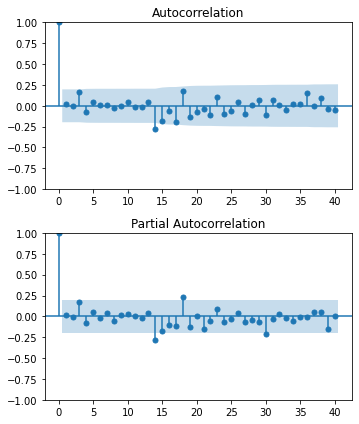
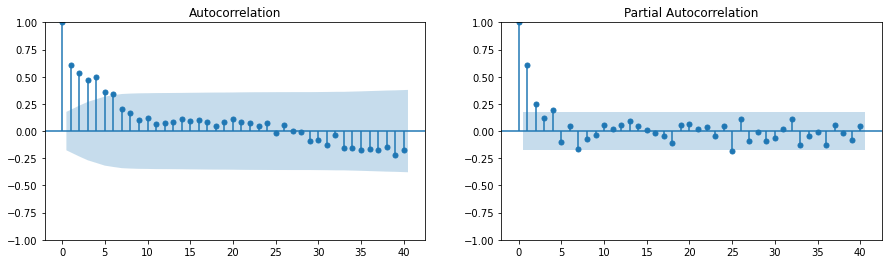
ACF, PACF
ACF, PACF에 대해서는 전 포스트에서 다루었다.
AR 모델의 차수 결정: PACF를 살펴보아 \(p\) 이후에 급격히 떨어지는 지점을 찾는다. 이 지점이 AR 모델의 추정 차수가 될 수 있다.
MA 모델의 차수 결정: ACF를 살펴보아 \(q\) 이후에 급격히 떨어지는 지점을 찾는다. 이 지점이 MA 모델의 추정 차수가 될 수 있다.
ARIMA 모델의 차수 결정: 차분 \(d\)를 적용한 후에도 비정상적인 패턴이 관찰되면, ACF와 PACF를 다시 살펴보아 AR 부분과 MA 부분의 차수를 결정한다.
auto_arima 함수는 주어진 시계열 데이터에 대해 최적의 ARIMA 모델을 자동으로 찾는다!
import pmdarima as pm# auto_arima 실행model = pm.auto_arima(data, start_p=2, start_q=2, test='adf', # ADF 검정을 사용하여 차분 결정 max_p=5, max_q=5, # 최대 p와 q 값 m=1, # 계절성 주기, 여기서는 비계절성 시계열이므로 1 d=None, # 차분 차수, None이면 자동 결정 seasonal=False, # 계절성 모델 사용 여부 start_P=1, D=None, trace=True, # 검색 과정의 정보를 출력 error_action='ignore', suppress_warnings=True, stepwise=True) # 단계별 검색 사용# 요약 정보 출력print(model.summary())
비선형성: ARIMA 모델은 선형 관계를 가정한다. 많은 실제 시계열 데이터는 비선형 패턴을 보이기 때문에, 이러한 비선형 패턴을 효과적으로 모델링하지 못할 수 있다.
계절성: 계절 ARIMA(Seasonal ARIMA) 모델은 계절성을 다루기 위해 개발되었지만, 계절성이 복잡하거나 비정기적인 시계열 데이터를 처리하는 데는 한계가 있다.
정상성: ARIMA 모델은 시계열 데이터가 정상성을 가정한다. 비정상 시계열 데이터는 차분 등의 방법으로 정상 시계열로 변환할 수 있지만, 이 과정에서 정보가 손실될 수 있으며, 모든 비정상 시계열이 적절히 정상화되는 것은 아니다. 또한, 차분을 통해 얻어진 시계열 데이터의 해석이 원본 데이터의 해석과 다를 수 있다.
모델 선택과 과적합의 위험: 적절한 ARIMA 모델을 선택하기 위해서는 \(p,d,q\)의 적절한 차수를 결정해야 한다. 모델 차수를 결정하는 과정에서 과적합(overfitting)이 발생할 수 있으며, 이는 모델의 예측 성능을 저하시킬 수 있다. AIC, BIC와 같은 기준을 사용하여 모델을 선택할 수 있지만, 이러한 기준만으로 최적의 모델을 항상 보장하지는 않는다.
동적 변화에 대한 제한적 대응: ARIMA 모델은 시계열 데이터의 고정된 패턴을 기반으로 예측을 수행한다. 시계열 데이터의 구조가 시간에 따라 변하는 경우(예: 금융 시장의 급변동), ARIMA 모델은 이러한 동적 변화에 효과적으로 대응하기 어려울 수 있다.
SARIMAX
Seasonal AutoRegressive Integrated Moving Average with eXogenous regressors
SARIMAX 모델은 ARIMA 모델을 기반으로 하면서 계절성 요소와 외생 변수를 추가하여 모델의 유연성과 정확성을 높였다. SARIMAX는 다양한 시계열 데이터, 특히 계절적 패턴과 외부 영향을 받는 데이터에 적합하다.
AR (AutoRegressive) 부분: 과거의 종속 변수 값(지연 값)이 미래 값에 영향을 미친다고 가정
MA (Moving Average) 부분: 과거의 예측 오차가 미래 예측에 영향을 미친다고 가정
Integration (차분) 부분: 비정상성(Non-stationarity) 데이터를 정상성(Stationarity) 데이터로 변환하기 위해 사용
Seasonal 요소: 계절성 패턴을 모델링. 계절성 AR 및 MA 구성 요소와 계절성 차분 차수를 포함할 수 있으며, 이들은 각각 \(P, D, Q\) 및 계절 주기 \(s\)에 의해 정의됨
Exogenous 변수 (\(\mathbf{X}\)): 모델에 외부에서 영향을 미치는 변수(예: 경제 지표, 마케팅 캠페인, 기상 조건 등)를 포함. 이 변수들은 종속 변수에 직접적인 영향을 미칠 수 있으며, 모델의 설명력과 예측력을 향상시킴.
import numpy as npimport pandas as pdfrom scipy.stats import normimport statsmodels.api as smimport matplotlib.pyplot as pltfrom datetime import datetime
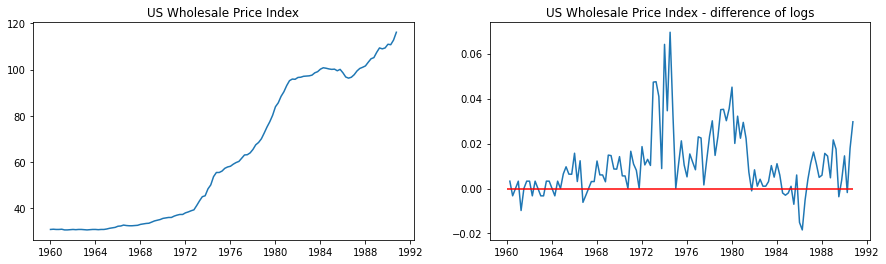
data = pd.read_stata('data/wpi1.dta')data.index = data.t# Set the frequencydata.index.freq="QS-OCT"data['ln_wpi'] = np.log(data['wpi'])data['D.ln_wpi'] = data['ln_wpi'].diff()# Graph datafig, axes = plt.subplots(1, 2, figsize=(15,4))# Levelsaxes[0].plot(data.index._mpl_repr(), data['wpi'], '-')axes[0].set(title='US Wholesale Price Index')# Log differenceaxes[1].plot(data.index._mpl_repr(), data['D.ln_wpi'], '-')axes[1].hlines(0, data.index[0], data.index[-1], 'r')axes[1].set(title='US Wholesale Price Index - difference of logs');
# get results for the full dataset but using the estimated parameters (on a subset of the data)mod = sm.tsa.statespace.SARIMAX(endog, exog=exog, order=(1,0,1))res = mod.filter(fit_res.params)