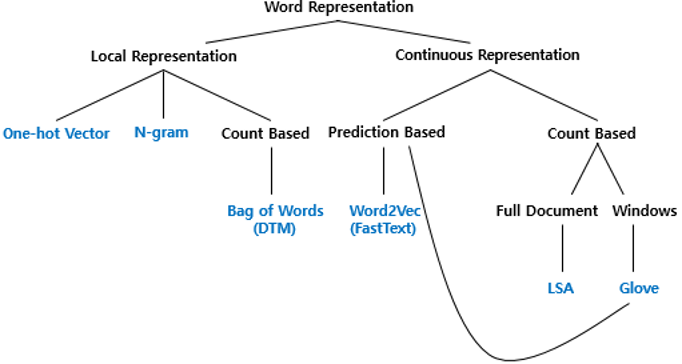
워드 임베딩(Word Embedding)은 자연어 처리(NLP)에서 단어를 고정된 크기의 실수 벡터로 변환하는 기술이다. 이번에는 GloVe와 FastText에 대해 알아보자.
카운트 기반 - LSA(Latent Semantic Analysis): DTM이나 TF-IDF 행렬과 같이 각 문서에서의 각 단어의 빈도수를 카운트 한 행렬이라는 전체적인 통계 정보를 입력으로 받아 차원을 축소(Truncated SVD)하여 잠재된 의미를 끌어내는 방법론 - 단어 의미의 유추 작업(Analogy task)에 성능이 떨어짐
예측 기반 - Word2Vec: 실제값과 예측값에 대한 오차를 손실 함수를 통해 줄여나가며 학습 - 임베딩 벡터가 윈도우 크기 내에서만 주변 단어를 고려하기 때문에 코퍼스의 전체적인 통계 정보를 반영하지 못함
글로브(GloVe)
카운트 기반, 예측기반을 모두 사용하는 방법론
윈도우 기반 동시 등장 행렬(window based co-occurrence matrix)
I like deep learning
I like NLP
I enjoy flying
카운트
I
like
enjoy
deep
learning
NLP
flying
I
0
2
1
0
0
0
0
like
2
0
0
1
0
1
0
enjoy
1
0
0
0
0
0
1
deep
0
1
0
0
1
0
0
learning
0
0
0
1
0
0
0
NLP
0
1
0
0
0
0
0
flying
0
0
1
0
0
0
0
동시 등장 확률(co-occurrence probability)
동시 등장 확률과 크기 관계 비(ratio)
k=solid
k=gas
k=water
k=fasion
\(P(k | ice)\)
0.00019
0.000066
0.003
0.000017
\(P(k | steam)\)
0.000022
0.00078
0.0022
0.000018
\(P(k | ice) / P(k | steam)\)
8.9
0.085
1.36
0.96
GloVe의 아이디어를 한 줄로 요약하면 ‘임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률(의 로그값)이 되도록 만드는 것’
import gensim.downloader as api# GloVe 모델 다운로드 및 로드glove_vectors = api.load("glove-wiki-gigaword-100") # 100차원 GloVe 벡터# "machine" 단어의 벡터 출력print("Vector for 'machine':")print(glove_vectors['machine'])# "learning" 단어의 벡터 출력print("Vector for 'learning':")print(glove_vectors['learning'])# 두 단어의 유사도 계산similarity = glove_vectors.similarity('machine', 'learning')print(f"Similarity between 'machine' and 'learning': {similarity}")# 가장 유사한 단어 5개 찾기similar_words = glove_vectors.most_similar('machine', topn=5)print("Top 5 words similar to 'machine':")for word, score in similar_words:print(f"{word}: {score}")
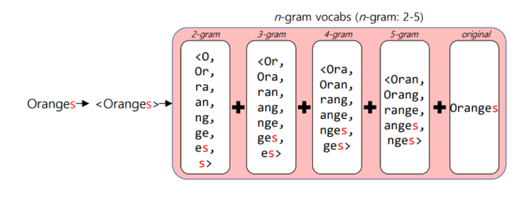
FastText의 인공 신경망을 학습한 후에는 데이터 셋의 모든 단어의 각 n-gram에 대해서 워드 임베딩이 됨.
subword를 통해 모르는 단어(OOV)에 대해서도 다른 단어와의 유사도를 계산할 수 있음.
Ex. ‘birthplace’는 학습되지 않고, ‘birth’와 ‘place’는 되었다면, FastText는 ‘birthplace’ 벡터를 얻을 수 있음.
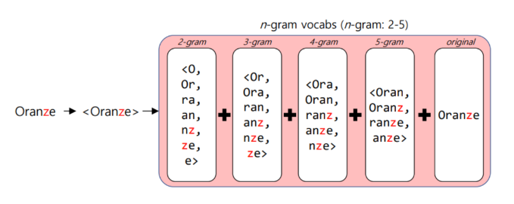
빈도 수가 적었던 단어(rare word)에 대한 대응 - Word2Vec은 등장 빈도가 적은 단어에 대해 임베딩 정확도가 낮음. - 하지만 FastText는 그 단어의 n-gram이 다른 단어의 n-gram과 겹치면 정확도 상승 - 또한 노이즈(오타 등)가 많은 코퍼스에서 강점을 가짐. (ex. oranze)
from gensim.models import FastTextfrom nltk.tokenize import word_tokenize# 예제 문서documents = ["The quick brown fox jumps over the lazy dog.","I love natural language processing and machine learning.","Word embeddings are a type of word representation that allows words to be represented as vectors.","Gensim is a useful library for text processing in Python.","Machine learning models can be used for a variety of tasks, including classification and regression.","Deep learning is a subset of machine learning that uses neural networks.","Text data requires preprocessing before it can be used in machine learning models.","Natural language processing involves the interaction between computers and humans using natural language.","The field of artificial intelligence includes machine learning and deep learning.","Python is a popular programming language for data science and machine learning.","In the world of data science, Python is a widely used programming language.","FastText is an extension of Word2Vec, developed by Facebook's AI Research lab.","It is particularly well-suited for text classification and representation learning.","Neural networks are a powerful tool for machine learning and artificial intelligence.","Preprocessing text data is a crucial step in natural language processing.","Data science involves using algorithms, data analysis, and machine learning to extract insights from data.","The history of natural language processing dates back to the 1950s.","Gensim provides efficient implementations of popular algorithms for word vector representations.","The applications of machine learning are vast and include fields such as finance, healthcare, and technology.","Understanding the context of a word is crucial for accurate natural language understanding.","Text classification is a common task in natural language processing.","FastText can be used to create word embeddings that capture the meaning of words in context.","The development of neural networks has significantly advanced the field of machine learning.","Python's libraries and frameworks make it a powerful tool for data scientists.","Machine learning algorithms can identify patterns and make predictions based on data.","Deep learning models are capable of learning complex patterns in data.","Natural language processing enables computers to understand and respond to human language.","The rise of artificial intelligence has led to significant advancements in many fields.","FastText supports both supervised and unsupervised learning.","Word embeddings are used to convert words into numerical vectors.","The performance of a machine learning model depends on the quality of the data and the choice of algorithm."]
# 문서 토큰화tokenized_docs = [word_tokenize(doc.lower()) for doc in documents]# FastText 모델 초기화model = FastText(vector_size=100, window=3, min_count=1)# 어휘 빌드model.build_vocab(corpus_iterable=tokenized_docs)# 모델 학습model.train(corpus_iterable=tokenized_docs, total_examples=len(tokenized_docs), epochs=10)# "machine" 단어의 벡터 출력print("Vector for 'machine':")print(model.wv['machine'])# "learning" 단어의 벡터 출력print("Vector for 'learning':")print(model.wv['learning'])# 두 단어의 유사도 계산similarity = model.wv.similarity('machine', 'learning')print(f"Similarity between 'machine' and 'learning': {similarity}")# 가장 유사한 단어 5개 찾기similar_words = model.wv.most_similar('machine', topn=5)print("Top 5 words similar to 'machine':")for word, score in similar_words:print(f"{word}: {score}")