증권사 리포트 텍스트 분석
Industry Monitoring using AI algorithm
<서범석. 2023. “AI 알고리즘을 이용한 산업 모니터링: 증권사 리포트 텍스트 분석”, BOK 이슈노트 제 2023-5호, 한국은행.>을 소개한다. 이 연구는 자연어처리 등 통계 기법을 이용하여, 증권사 애널리스트의 기업 평가 보고서를 토대로 산업별 모니터링 정보를 추출하였다.
논문 요약
선행연구
경제 분석을 위한 자연어 처리의 활용
- 데이터
- 뉴스 텍스트: 언론 견해 반영 (Baker et al., 2016; Shapiro et al., 2020).
- SNS 및 검색 데이터 (Sun et al., 2016).
- 기업 회계 및 평가 보고서(Lewis and Young, 2019).
- 기존 연구의 초점:
- 사전접근법 또는 통계 모형 기반의 감성분석(sentiment analysis) 및 토픽 모델링
- 최근은 복잡한 인공신경망 모형 이용
- 분석
- 물가, 주가 등 가격지표 예측(Kalamara et al. 2022, Li et al. 2020)
- 위기 지표, 불확실성 지표 등 새로운 경제정보 산출(Li et al 2009, Baker et al 2016)
- 사기 탐지(fraudulent detection)(Li et al. 2020)
- 기업의 지속가능성 분류(Te Liew et al. 2014)
- 신용 평가(credit scoring)(Yap et al. 2011)
- 국내 연구
- Lee et al. (2019): 뉴스 텍스트 분석을 통해 통화정책 서프라이즈 지수를 산출.
- 서범석(2022a): 뉴스 텍스트로 경기 예측 및 부문별 텍스트 지표 개발.
- Seo et al. (2022b): 트랜스포머(Transformer) 기반의 뉴스심리지수 개발.
- 한승욱 외(2022): 인플레이션 어조지수 평가.
- 트위터 데이터 활용 핀테크 트렌드 분석 (김도희·김민정, 2022).
- ESG 보고서를 통한 ESG 방향성 평가 (박수빈·이용규, 2022).
- 본 연구의 차별점
- 대부분의 기존 연구는 단순 경제 지표 예측 또는 일회성 평가에 집중.
- 본 연구는 산업별 업황 분석 및 변동요인 파악에 유용한 텍스트 지표를 제시하고, 추정 과정의 알고리즘화 가능성을 논함
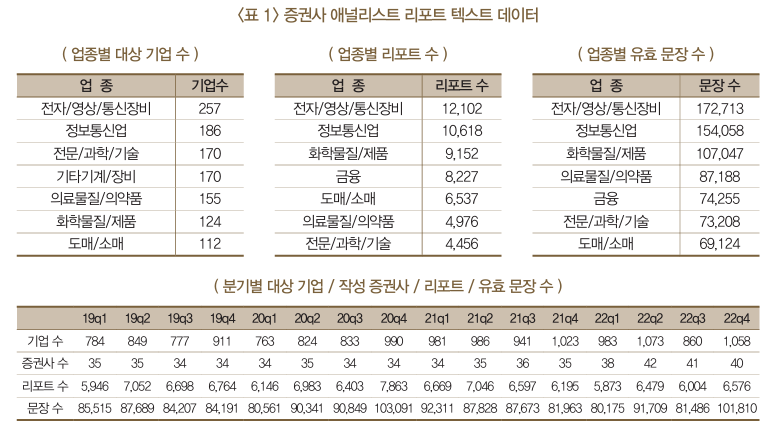
데이터
리포트 수집
- 2019년~2022년 증권사 기업 평가 보고서 12만 8천건 수집
- 52개 증권사 1,079명의 애널리스트가 작성한 2,283개 기업에 대한 기업 분석 보고서로 월평균 2천 문건
- 산업 및 거시 분석 보고는 제외, 개별 기업 분석 보고서만 수집
- 개별 기업에 대한 미시적 평가를 바탕으로 국가 전체에 대한 거시적 효과를 분석하기 위함
- 보고서 발간 시점 기준으로, 분기별로 취합
텍스트 데이터 추출
- 전처리 과정
- Bag-of-words 데이터로 전환
- 중복 문장, 단순 수치 언급, 이해관계 고지 등 문장 제거로 약 145만개 유효 문장 선별
- 약 145만개의 유효 문장 선별
텍스트 기반 산업 모니터링 정보 추출
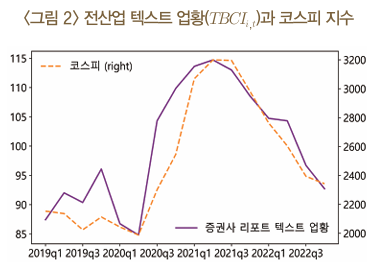
텍스트 기반 업황 지수(Text-based Business Confidence Indicator, TBCI)
- 감성분석(sentiment analysis) 모형 적용
- 트랜스포머(transformer) 기반의 통계 모형 구축
- 문장을 긍정, 부정 또는 중립으로 분류
- 미리 학습한 Pre-trained 모형에 Seo et al.(2022 b)의 뉴스 데이터 일부 학습
\(TBCI_{i,t} = \frac{X_{i,t} - \overline{X}_{i,.}}{s_{i,.}} \times 10 + 100,\)
\(X_{i,t} = \frac{\sum_{s \in S_{i,t}} \left[I(s \in P) - I(s \in N)\right]}{\sum_{s \in S_{i,t}} \left[I(s \in P) + I(s \in N)\right]},\)
\(\overline{X}_{i,.} = \frac{\sum_{t} X_{i,t}}{T},\)
\(s_{i,.} = \sqrt{\frac{\sum_{t} (X_{i,t} - \overline{X}_{i,.})^2}{T - 1}}.\)
- \(P\)와 \(N\)은 각각 가능한 모든 긍정 및 부정 문장의 집합
- \(S_{i,t}\)는 증권사 리포트에서 추출한 업종 \(i\)의 \(t\)기 문장 샘플 중복집합(multiset)
즉, 업황 \(TBCI_{i,t}\)는 업종 \(i\)와 관련한 증권사 리포트의 문장 논조를 분류한 뒤, 산출한 긍정 문장과 부정 문장 수의 차이를 두 수의 합계로 나누어 추정하고, 장기평균을 이용해 표준화하여 산출
기업경영환경 변화 요인표 (Business Condition Factors, BC-factors)
- 키워드 빈도 분석 적용
- 경제적으로 의미 없는 불용어 제거
- 문장구조를 요인, 관계언, 평가 로 분해하여 요인 표현 품사 제거 후 Trigram 방법으로 기업경영환경 변화요인 추정
- (예) ‘신모델 출시 효과로 전분기 대비 판매 호조를 보이면서 매출과 영업이익에서 견조한 성장세’ 에서 신모델·출시·효과, 판매·호조·보이
\(BC\text{-}factors^5_{i,t} = \{ (\omega^{[K]}, \dots, \omega^{[K-4]}) \mid \omega^{[k]} = f(v_{(k)}) \\ , v = m_{U_{i,t} \setminus W}(\omega), \\ v_{(k)} \text{ is the } k^\text{th} \text{ order statistic of } v. \}\)
- \(U_{i,t}\)는 증권사 리포트에서 추출한 업종 \(i\)의 \(t\)기 Trigram 패턴 샘플의 중복집합
- \(m_A(\omega)\)는 multiplicity function, 즉 \(A\)에 나타나는 \(\omega\)의 개수
- \(W\)는 Trigram 패턴 불용어 집합
- \(K\)는 불용어를 제외한 Trigram 패턴의 수, 즉 \(K =|Supp(U_{i,t}\W)|\)

참고문헌
- 서범석 (2023). BOK 이슈노트[제2023-5호] AI 알고리즘을 이용한 산업모니터링: 증권사 리포트 텍스트 분석